数据并行部署¶
vLLM 支持数据并行部署,其中模型权重被复制到独立的实例/GPU 上,以处理独立的请求批次。
这适用于稠密模型和 MoE(混合专家)模型。
对于 MoE 模型,特别是像 DeepSeek 这样采用 MLA(多头潜在注意力)的模型,对注意力层使用数据并行,而对专家层使用专家并行或张量并行(EP 或 TP)可能是有利的。
在这些情况下,数据并行(DP)的各个 rank 并非完全独立。前向传播必须对齐,并且在每次前向传播期间,所有 rank 的专家层都需要同步,即使待处理的请求数量少于 DP rank 的数量。
默认情况下,专家层形成一个大小为 DP × TP 的张量并行组。要使用专家并行,请包含 --enable-expert-parallel 命令行参数(在多节点情况下,所有节点都需要设置)。有关启用 EP 后注意力层和专家层行为差异的详细信息,请参阅专家并行部署。
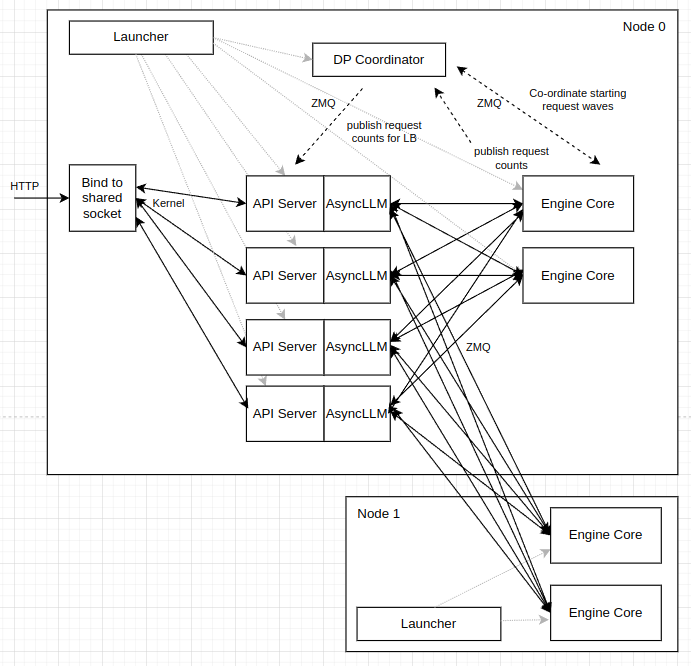
在 vLLM 中,每个 DP rank 都作为一个独立的“核心引擎”进程部署,通过 ZMQ 套接字与前端进程通信。数据并行注意力可以与张量并行注意力结合使用,在这种情况下,每个 DP 引擎拥有的工作进程数量等于配置的 TP 大小(每个 GPU 一个工作进程)。
对于 MoE 模型,当任何 rank 中有请求正在处理时,我们必须确保在没有请求调度的所有 rank 中执行空的“虚拟”前向传播。这是通过一个独立的 DP 协调器进程处理的,该进程与所有 rank 通信,并且每 N 步执行一次集体操作,以确定所有 rank 何时变为空闲状态并可以被暂停。当 TP 与 DP 结合使用时,专家层形成一个大小为 DP × TP 的组(默认使用张量并行,如果设置了 --enable-expert-parallel,则使用专家并行)。
在任何情况下,在 DP rank 之间进行请求负载均衡都是有益的。对于在线部署,可以通过考虑每个 DP 引擎的状态来优化这种均衡,特别是其当前已调度和等待(排队)的请求以及 KV 缓存状态。每个 DP 引擎都有独立的 KV 缓存,通过智能地引导提示,可以最大化前缀缓存的效益。
本文档重点介绍在线部署(使用 API 服务器)。DP + EP 也支持离线使用(通过 LLM 类),示例请参阅 examples/offline_inference/data_parallel.py。
在线部署支持两种不同的模式:自带内部负载均衡的独立模式,或外部逐 rank 进程部署和负载均衡模式。
内部负载均衡¶
vLLM 支持“独立”的数据并行部署,暴露单个 API 端点。
只需在 vllm serve 命令行参数中包含例如 --data-parallel-size=4 即可配置。这将需要 4 个 GPU。它可以与张量并行结合使用,例如 --data-parallel-size=4 --tensor-parallel-size=2,这将需要 8 个 GPU。在规划 DP 部署时,请记住 --max-num-seqs 是每个 DP rank 的限制。
在多个节点上运行单个数据并行部署需要在每个节点上运行不同的 vllm serve,并指定哪些 DP rank 应在该节点上运行。在这种情况下,仍然只有一个 HTTP 入口点 - API 服务器只在一个节点上运行,但不一定要与 DP rank 位于同一节点。
这将在单个 8-GPU 节点上运行 DP=4, TP=2:
这将在头节点上运行 DP=4 的 rank 0 和 1,在第二个节点上运行 rank 2 和 3:
# Node 0 (with ip address 10.99.48.128)
vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
# Node 1
vllm serve $MODEL --headless --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
这将在第一个节点上只运行 DP=4 的 API 服务器,在第二个节点上运行所有引擎:
# Node 0 (with ip address 10.99.48.128)
vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 0 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
# Node 1
vllm serve $MODEL --headless --data-parallel-size 4 --data-parallel-size-local 4 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
这种 DP 模式也可以与 Ray 一起使用,通过指定 --data-parallel-backend=ray:
使用 Ray 时有几个显著差异:
- 只需要一个启动命令(在任何节点上)即可启动所有本地和远程 DP rank,因此相比在每个节点上分别启动更加方便
- 无需指定
--data-parallel-address,运行命令的节点将自动作为--data-parallel-address - 无需指定
--data-parallel-rpc-port - 当单个 DP 组需要多个节点时,例如 单个模型副本需要在至少两个节点上运行时,请确保设置
VLLM_RAY_DP_PACK_STRATEGY="span",在这种情况下--data-parallel-size-local将被忽略并自动确定 - 远程 DP rank 将根据 Ray 集群的节点资源进行分配
目前,内部 DP 负载均衡在 API 服务器进程内完成,基于每个引擎的运行队列和等待队列。未来可以通过集成 KV 缓存感知逻辑来使其更加复杂。
使用此方法部署大型 DP 规模时,API 服务器进程可能成为瓶颈。在这种情况下,可以使用正交的 --api-server-count 命令行选项进行扩展(例如 --api-server-count=4)。这对用户是透明的 - 仍然暴露单个 HTTP 端点/端口。请注意,这种 API 服务器扩展是“内部”的,仍然局限于“头”节点。
混合负载均衡¶
混合负载均衡介于内部和外部方法之间。每个节点运行自己的 API 服务器,只将请求排队到该节点上共置的数据并行引擎。上游负载均衡器(例如入口控制器或流量路由器)将用户请求分发到这些每节点端点。
启用此模式需使用 --data-parallel-hybrid-lb,同时仍使用全局数据并行大小启动每个节点。与内部负载均衡的关键区别是:
- 必须提供
--data-parallel-size-local和--data-parallel-start-rank,以便每个节点知道它拥有哪些 rank - 与
--headless不兼容,因为每个节点都暴露一个 API 端点 - 根据本地 rank 的数量在每个节点上扩展
--api-server-count
在这种配置中,每个节点保持本地调度决策,这减少了跨节点流量,并避免了在较大 DP 规模下单个节点的瓶颈。
外部负载均衡¶
对于更大规模的部署,尤其是处理数据并行 rank 的编排和负载均衡时,外部处理可能更有意义。
在这种情况下,将每个 DP rank 视为一个独立的 vLLM 部署会更加方便,每个 rank 都有自己的端点,并由外部路由器在它们之间平衡 HTTP 请求,利用来自每个服务器的适当实时遥测数据进行路由决策。
对于非 MoE 模型,这已经可以简单地实现,因为每个部署的服务器都是完全独立的。为此不需要使用任何数据并行命令行选项。
我们支持 MoE DP+EP 的等效拓扑结构,可以通过以下命令行参数进行配置。
如果 DP 等级位于同一位置(同一节点/IP 地址),则使用默认的 RPC 端口,但必须为每个等级指定不同的 HTTP 服务器端口:
# Rank 0
CUDA_VISIBLE_DEVICES=0 vllm serve $MODEL --data-parallel-size 2 --data-parallel-rank 0 \
--port 8000
# Rank 1
CUDA_VISIBLE_DEVICES=1 vllm serve $MODEL --data-parallel-size 2 --data-parallel-rank 1 \
--port 8001
对于多节点情况,还必须指定 rank 0 的地址/端口:
# Rank 0 (IP 地址为 10.99.48.128)
vllm serve $MODEL --data-parallel-size 2 --data-parallel-rank 0 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
# Rank 1
vllm serve $MODEL --data-parallel-size 2 --data-parallel-rank 1 \
--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
在这种场景下,协调器进程也会运行,并与 DP rank 0 引擎位于同一位置。
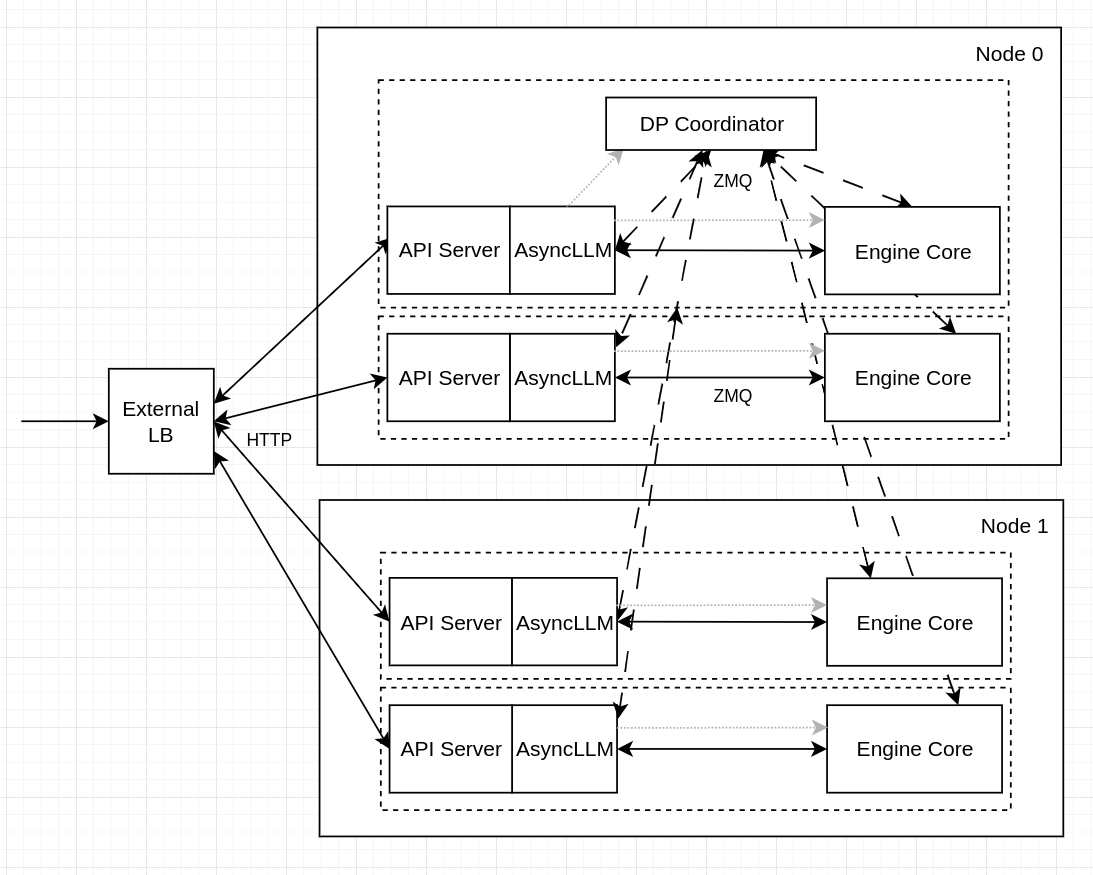
在上图中,每个虚线框对应一次独立的 vllm serve 启动 - 例如,这些可以是独立的 Kubernetes Pod。