分离式编码器¶
分离式编码器 将多模态 LLM 的视觉编码器阶段运行在与预填充/解码阶段分离的进程中。将这两个阶段部署在独立的 vLLM 实例中可带来三个实际优势:
- 独立、细粒度的扩展能力
- 更低的首次生成时间 (TTFT)
- 跨进程复用和缓存编码器输出
设计文档:https://docs.google.com/document/d/1aed8KtC6XkXtdoV87pWT0a8OJlZ-CpnuLLzmR8l9BAE
1 动机¶
1. 独立、细粒度的扩展能力¶
- 视觉编码器较为轻量,而语言模型的规模要大几个数量级。
- 语言模型可以并行化处理,而不会影响编码器集群。
- 编码器节点可以独立地添加或移除。
2. 更低的首次生成时间 (TTFT)¶
- 纯文本请求完全绕过视觉编码器。
- 编码器输出仅在需要的注意力层注入,从而缩短预填充的关键路径。
3. 跨进程复用和缓存¶
- 进程内编码器将复用限制在单个工作进程中。
- 远程共享缓存允许任何工作进程检索已有的嵌入向量,从而避免冗余计算。
2 使用示例¶
当前的参考路径是 ExampleConnector。
以下可直接运行的脚本展示了工作流程:
1 个编码器实例 + 1 个 PD 实例:
examples/online_serving/disaggregated_encoder/disagg_1e1pd_example.sh
1 个编码器实例 + 1 个预填充实例 + 1 个解码实例:
examples/online_serving/disaggregated_encoder/disagg_1e1p1d_example.sh
3 测试脚本¶
请参考目录 tests/v1/ec_connector
4 开发¶
分离式编码通过运行两个部分实现:
- 编码器实例 – 执行视觉编码的 vLLM 实例。
- 预填充/解码 (PD) 实例 – 运行语言预填充和解码。
- PD 可以是一个普通的单个实例(使用
disagg_encoder_example.sh,E->PD),也可以是分离的实例(使用disagg_epd_example.sh,E->P->D)
- PD 可以是一个普通的单个实例(使用
连接器负责将编码器缓存 (EC) 的嵌入向量从编码器实例传输到 PD 实例。
所有相关代码位于 vllm/distributed/ec_transfer。
关键抽象¶
- ECConnector – 用于检索编码器生成的 EC 缓存的接口。
- 调度器角色 – 检查缓存是否存在并调度加载。
- 工作进程角色 – 将嵌入向量加载到内存中。
下图展示了分离式编码器的工作流程:
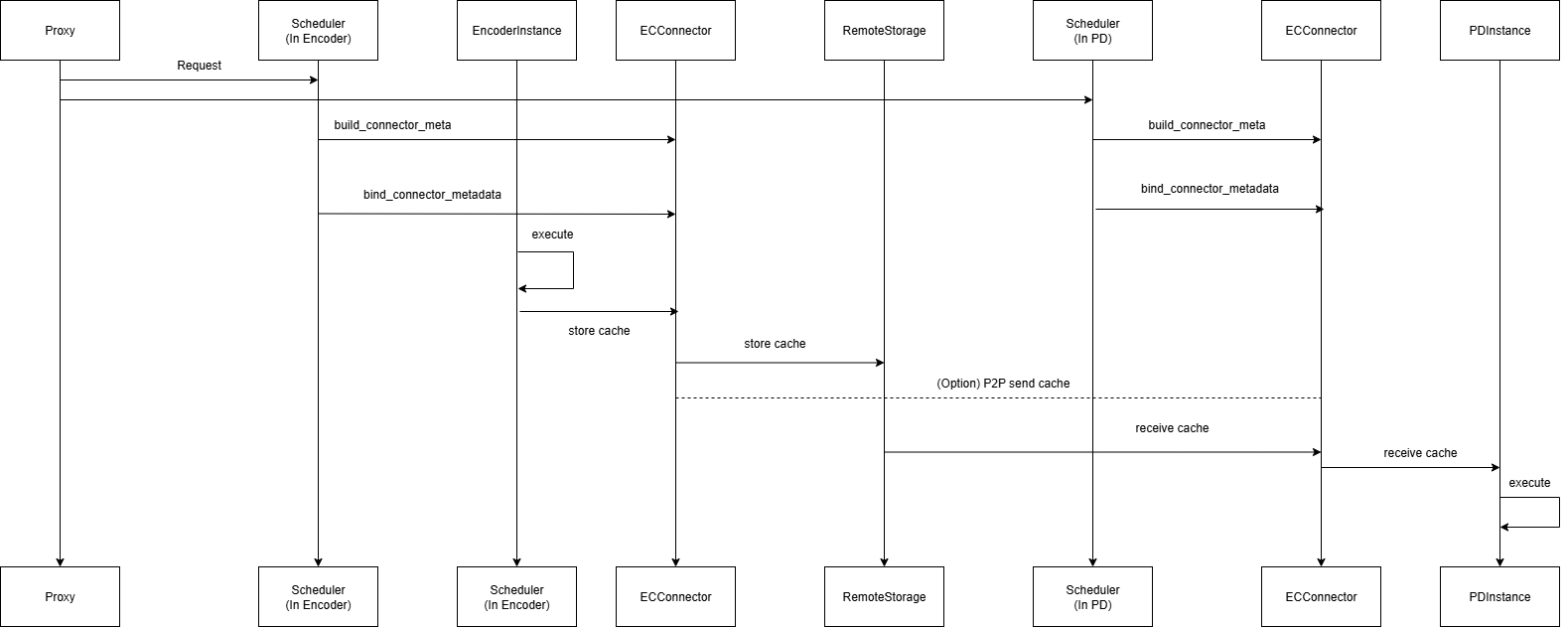
对于 PD 分离部分,预填充实例接收缓存的方式与上述分离式编码器流程完全相同。预填充实例执行 1 步(预填充 -> 输出 1 个 token),然后将 KV 缓存传输给解码实例以完成剩余的执行。KV 传输部分纯粹发生在 PD 实例执行之后。
docs/features/disagg_prefill.md 简要介绍了分离式预填充 (v0) 的概念。
我们使用来自 vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py 的 NixlConnector 创建示例设置,并参考 tests/v1/kv_connector/nixl_integration/toy_proxy_server.py 来实现 P 和 D 之间的 KV 传输。