混合 KV 缓存管理器¶
Warning
本文档基于提交 458e74 编写。此功能仍处于早期阶段,可能会发生变化。
什么是混合模型?¶
许多最近的“混合”LLM 在一个模型中结合了多种注意力类型。例如:
- 滑动窗口注意力(sw)+ 全注意力(full):gpt-oss、Gemma 2/3、Ministral、cohere 等。
- Mamba + 全注意力:Bamba、Jamba、Minimax 等。
- 局部分块注意力 + 全注意力:Llama4
为了高效地服务这些模型,我们的 KVCacheManager 必须:
- 为不同的层类型分配不同的槽位,例如:
- 全注意力层:为所有 token 保留槽位。
- 滑动窗口层:仅为最近的
sliding_window_size个 token 保留槽位。
- 支持特定于层的前缀缓存规则,例如:
- 全注意力:缓存命中前缀要求所有 token 都保留在 KV 缓存中。
- 滑动窗口:缓存命中前缀仅要求最后的
sliding_window_size个 token 保留在 KV 缓存中。
定义¶
- kv 隐藏大小:为单个层的一个 token 的 KV 缓存存储的字节数。
- 块:为 KV 缓存保留的内存被划分为多个具有相同页大小(定义如下)的块。
- 块大小:一个块内的 token 数量。
-
页大小:一个块的物理内存大小,定义为:
\[ \text{层数} \times \text{块大小} \times \text{kv 隐藏大小} \]层数并不意味着模型中的总层数。确切数量取决于本文档中的上下文。Note
这与代码中的
KVCacheSpec.page_size_bytes不同,后者定义为:\[ \text{块大小} \times \text{kv 隐藏大小} \]
分配¶
高层思路¶
我们为所有层类型使用一个内存池。内存池被分割成多个具有相同页大小的块。KVCacheManager 根据其注意力类型为不同的层分配不同数量的块。
核心挑战是确保每种层类型都使用相同的页大小。对于仅全注意力的模型,页大小很简单,定义为:
然而,在混合模型中,隐藏层数因注意力类型而异,这通常会产生不匹配的页大小。下面的案例展示了我们如何统一它们。
案例 1:玩具模型¶
让我们从一个玩具示例开始:一个模型有 1 个全注意力层和 3 个滑动窗口注意力层。所有层具有相同的 kv 隐藏大小。
我们让每个块为一个层保存 块大小 个 token,因此:
KVCacheManager 为每一层分配不同数量的块。
此案例仅是一个玩具示例。对于真实模型,请参阅以下案例。
案例 2:相同 kv 隐藏大小 和规则模式¶
当模型有更多层时,例如,20 个滑动窗口注意力层和 10 个全注意力层,且具有相同的 kv 隐藏大小。每层调用一次分配器(30 次调用)是可以的,但会变得低效。作为一种解决方案,我们将需要相同数量块的层的分配进行分组,以减少调用次数。
分组是可行的,因为不同类型的层数之间通常存在一个良好的比例。例如:
- Gemma-2:1 个 sw : 1 个 full
- Llama 4:3 个 local : 1 个 full
我们的示例可以视为 2 个 sw : 1 个 full。我们可以像模型中有 2 个 sw 和 1 个 full 一样分配块,并将结果重复 10 次,以生成 30 层的 块 ID。页大小变为:
假设 块大小 为 16,滑动窗口大小为 32,请求长度为 112,那么对于上述示例模型,我们需要分配 11 个块(0-6 给 full,7-8 给 sw 组 1,9-10 给 sw 组 2)。
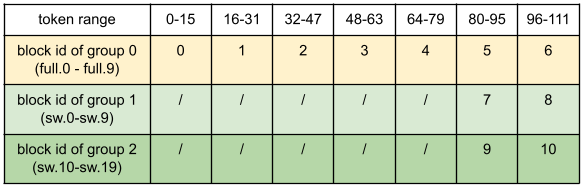
这里,“/”表示不需要块(滑动窗口层不需要为早期 token 保留槽位)。
请参阅下面的正式定义。这些层被划分为多个 KV 缓存组,以便:
- 每个组内注意力类型相同:每个组只包含具有相同注意力类型的层,因此对于给定的请求需要相同数量的块。这使得同一组中的层可以共享相同的块 ID 而不会浪费内存。
- 组间页大小相同:因为我们的内存池只有一个页大小。
我们的示例模型被划分为 3 个 KV 缓存组:
- 组 0:10 个全注意力层(full.0 - full.9)
- 组 1:10 个滑动窗口注意力层(sw.0 - sw.9)
- 组 2:10 个滑动窗口注意力层(sw.10 - sw.19)
显然,它满足规则 1。对于规则 2,所有 3 个组都有
作为它们的页大小。
案例 3:相同 kv 隐藏大小 且无规则模式¶
不幸的是,并非所有模型都有如此良好的比例,案例 2 中的方法会产生太多小组。例如,Gemma-3-27b 有 52 个滑动窗口注意力层和 10 个全注意力层。在案例 2 的约束下,它将是 26 个滑动窗口组和 5 个全注意力组,每组包含 2 层。分配仍然低效。为了减少 KV 缓存组的数量,我们使用所有注意力类型中最小的层数对层进行分组。例如,Gemma-3-27b 中每组 min(52, 10)=10 层。然后分组结果为:
- 组 0:10 个全注意力层(full.0 - full.9)
- 组 1:10 个滑动窗口注意力层(sw.0 - sw.9)
- 组 2:10 个滑动窗口注意力层(sw.10 - sw.19)
- ...
- 组 6:10 个滑动窗口注意力层(sw.40 - sw.49)
- 组 7:2 个滑动窗口注意力层(sw.50 - sw.51)和 8 个填充层
如果此启发式方法在新模型出现时导致不良结果(例如,20 个 full + 30 个 sw,组大小应为 10 而不是 20),我们将更新此算法。
此案例发生在 Gemma-3 系列模型中,以及案例 2 中的模型,但引入了鹰式推测解码,这会引入一个全注意力层。该解决方案存在一些内存浪费,并不完美。请报告任何填充开销变得不可接受的情况,以便我们可以改进算法。
案例 4:不同 kv 隐藏大小(主要是混合 Mamba 模型)¶
某些架构(例如,Bamba、Jamba、Minimax)将标准注意力层与 Mamba 层交错,其中每个 Mamba 层每 token 的状态大小可能比注意力层的 kv 隐藏大小 大得多。因为我们只支持所有组的一个页大小,所以我们必须协调这些不同的隐藏大小。
当前的算法是:
- 增加注意力层的
块大小,直到 $$ \text{块大小} \times \text{kv 隐藏大小}{\text{att}} \ge \text{状态大小} $$} - 将每层的 Mamba 状态填充到 $$ \text{块大小} \times \text{kv 隐藏大小}_{\text{att}} $$
- 应用案例 3 中的分组策略。
Note
这可能导致注意力层的 块大小 超过 400,这太大了。另一种填充策略是增加 块大小,直到
这种填充策略仍在进行中。
案例 5:KV 共享¶
KV 共享指的是一个层使用另一个层的 KV 缓存,例如 gemma-3n。 在这些模型中,KVCacheManager 忽略所有具有 KV 共享的层,仅为需要 KV 缓存的层分配 KV 缓存,并且在模型运行器中做了一些补丁,以将分配结果应用于 KV 共享层。
为简单起见,本节假设 block_size=1。
高层思路¶
块池使用一个类似 tuple(block_hash, group_id) -> block 的字典来缓存完整的块。这意味着不同组的相同 token 会被独立地缓存和逐出。
当新请求到达时,我们检查每个组的缓存命中前缀,并返回这些组的交集作为该请求的缓存前缀。有关检查单个组的缓存命中及执行交集操作的详细算法,请参见下文。
情况 0:仅支持全注意力机制的模型¶
对于全注意力层,会为请求中的所有 token 分配块。底层设计的详细信息,请参见前缀缓存。
为了找到请求的最长缓存命中前缀,我们从左(第一个块)到右(最后一个块)枚举,检查块是否已缓存,遇到缓存未命中时退出。例如,在下面的示例中(蓝色块表示已缓存),我们将返回前 7 个 token(0-6)作为缓存命中前缀:

情况 1:仅支持滑动窗口注意力机制的模型¶
对于滑动窗口注意力层,内存分配的一种朴素实现是为 sliding_window_size 个块分配内存,并以轮询方式填充这些块。但这种朴素的实现与前缀缓存不兼容,因此我们没有采用这种设计。在 vLLM 中,我们为不同的 token 分配不同的块,并释放滑动窗口之外的块。
对于新请求,缓存命中前缀仅要求最后 sliding_window_size - 1 个 token 被缓存。 假设 sliding_window_size = 4 且 block_size = 1,请求是一个包含 15 个 token 的提示(蓝色块表示已缓存):

有 3 种可能的缓存命中前缀:
- 缓存命中长度为 5,预填充计算范围为 [2, 3, 4] → [5, 6, …, 14]
- 缓存命中长度为 6,预填充计算范围为 [3, 4, 5] → [6, 7, …, 14]
- 缓存命中长度为 14,预填充计算范围为 [11, 12, 13] → [14](最高效)
我们可以从右到左检查缓存命中,并在找到匹配时提前退出。这与全注意力机制相反,后者是从左到右检查,并在匹配失败时提前退出。一个潜在的缺点(与全注意力机制相比)是,当没有匹配时,我们最终需要遍历整个 token 列表,而这通常是一个常见情况。这可能会造成不可忽视的开销,但在“全注意力 + 滑动窗口注意力”的组合下,如后文所述,是可以接受的。
情况 2:滑动窗口注意力 + 全注意力模型¶
第一个问题是如何找到缓存命中前缀。我们需要通过以下方式“交集”全局注意力层和滑动窗口注意力层的缓存命中:
- 获取全注意力机制的最长缓存命中(从左到右扫描)
- 在该长度范围内,获取滑动窗口注意力机制的最长缓存命中。实现方式是从全注意力机制的缓存命中长度开始,从右到左检查缓存命中。
可以确保滑动窗口注意力层的结果缓存命中也是全注意力层的缓存命中。这比分别找到每个组的所有可能前缀并执行交集更高效,因为我们的方法可以在没有缓存命中时提前退出。
该算法适用于恰好有两种注意力类型的模型:全注意力 + X,其中 X 可以是任意高效注意力算法,如滑动窗口、llama 4 局部注意力或 mamba。它不支持没有全注意力层的模型,也不支持具有超过两种注意力类型的模型。对于本文撰写时的大多数混合模型来说,这已经足够了。
第二个问题是缓存逐出策略。目前,我们为所有 KV 缓存组使用一个 LRU 队列。当块被释放时(因为请求已完成或块超出滑动窗口),块会被添加到 LRU 队列中。
情况 3:mamba 模型¶
mamba 模型的前缀缓存支持正在进行中。一旦实现,具有 mamba 层 + 全注意力层的模型可以通过情况 2 中的“全注意力 + X”算法得到支持。
实现¶
概览¶
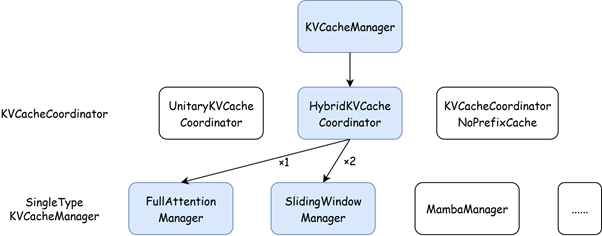
KVCacheManager 被组织为 3 层:
- KVCacheManager:调度器与 KV 缓存管理系统之间的接口。
- KVCacheCoordinator:协调每个组的 SingleTypeKVCacheManager,以生成请求的分配结果。根据模型的配置,选择以下协调器之一:
- KVCacheCoordinatorNoPrefixCache:在前缀缓存被禁用时使用。
- UnitaryKVCacheCoordinator:如果只有一个 KV 缓存组。前缀缓存逻辑被简化,因为不需要交集操作。
- HybridKVCacheCoordinator:处理恰好两个 KV 缓存组(必须包含一个全注意力组和一个其他高效注意力组)。其他情况未实现。你可以禁用前缀缓存以使用 KVCacheCoordinatorNoPrefixCache。
- SingleTypeKVCacheManager:每个实例管理一个 KV 缓存组的分配和前缀缓存,实现特定注意力类型的逻辑(例如,全注意力、滑动窗口、Mamba)。
上图中蓝色框显示了具有 10 个全注意力层和 20 个滑动窗口注意力层的情况,因此:
- 使用
HybridKVCacheCoordinator - 为 3 个
KVCacheGroup使用 1 个FullAttentionManager和 2 个SlidingWindowManager。
内存布局¶
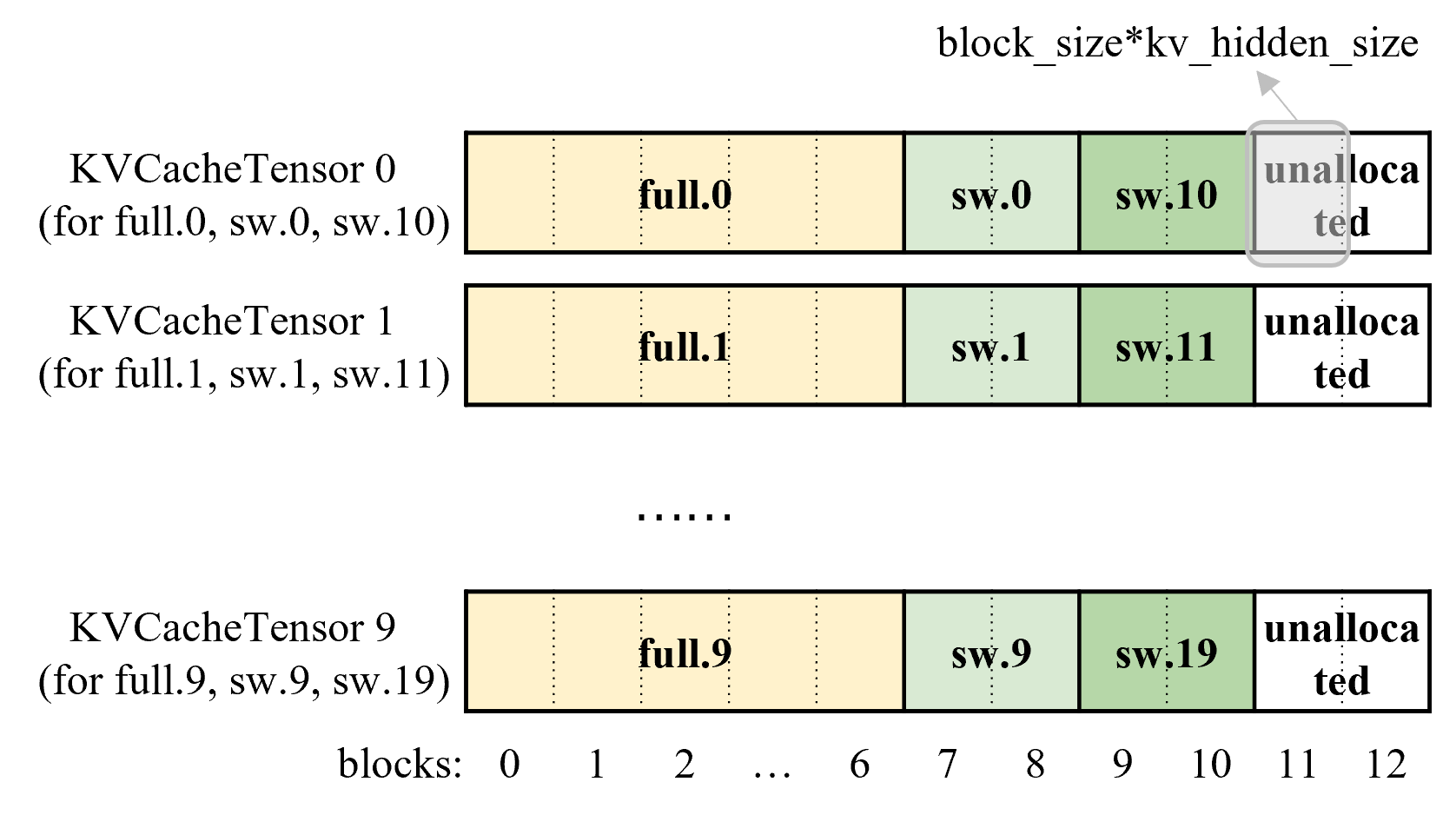
对于一个具有 n 个 KVCacheGroup 的模型,每个组有 m 层,我们分配 m 个缓冲区。每个缓冲区由 n 层共享,每个组各一层。
下图展示了一个具有 10 个全注意力层(full.0 - full.9)和 20 个滑动窗口注意力层(sw.0-sw.19)的模型。它遵循“分配”部分中的“情况 2”,并被分为 3 个组:
- 组 0:10 个全注意力层(full.0 - full.9)
- 组 1:10 个滑动窗口注意力层(sw.0 - sw.9)
- 组 2:10 个滑动窗口注意力层(sw.10 - sw.19)
对于一个请求,我们分配 11 个块,其中 block_id 0-6 分配给组 0,7-8 分配给组 1,9-10 分配给组 2。
通过这样的示例,物理内存被划分为 10 个缓冲区(KVCacheTensor 0 - KVCacheTensor 9)。每个缓冲区由 3 层共享(例如,KVCacheTensor 0 由组 0 的 full.0、组 1 的 sw.0 和组 2 的 sw.10 共享),并被划分为大小为 block_size * kv_hidden_size 的块。这 3 个注意力层的 KV 缓存会根据分配的 block_ids 保存到缓冲区的不同块中:
Note
一个逻辑“块”被映射到物理内存的 10 个缓冲区中的 10 个块。