Fused MoE Modular Kernel¶
Introduction¶
FusedMoEModularKernel 的实现位于 此处
根据输入激活的格式,FusedMoE 的实现大致可分为两类:
- Contiguous / Standard / Non-Batched(连续 / 标准 / 非批处理),以及
- Batched(批处理)
Note
本文档中术语 Contiguous、Standard 和 Non-Batched 可互换使用。
输入激活的格式完全取决于所使用的 All2All Dispatch 类型:
- 在 Contiguous 变体中,All2All Dispatch 返回形状为 (M, K) 的连续张量,以及形状为 (M, num_topk) 的 TopK Ids 和 TopK 权重。请参考
DeepEPHTPrepareAndFinalize查看示例。 - 在 Batched 变体中,All2All Dispatch 返回形状为 (num_experts, max_tokens, K) 的张量。在此情况下,订阅同一专家的激活/令牌被批量处理在一起。请注意,并非张量中的所有条目都有效。该激活张量通常伴随一个大小为
num_experts的expert_num_tokens张量,其中expert_num_tokens[i]表示订阅第 i 个专家的有效令牌数量。请参考PplxPrepareAndFinalize或DeepEPLLPrepareAndFinalize查看示例。
FusedMoE 操作通常由多个操作组成,在 Contiguous 和 Batched 变体中均如此,具体如以下图表所示:
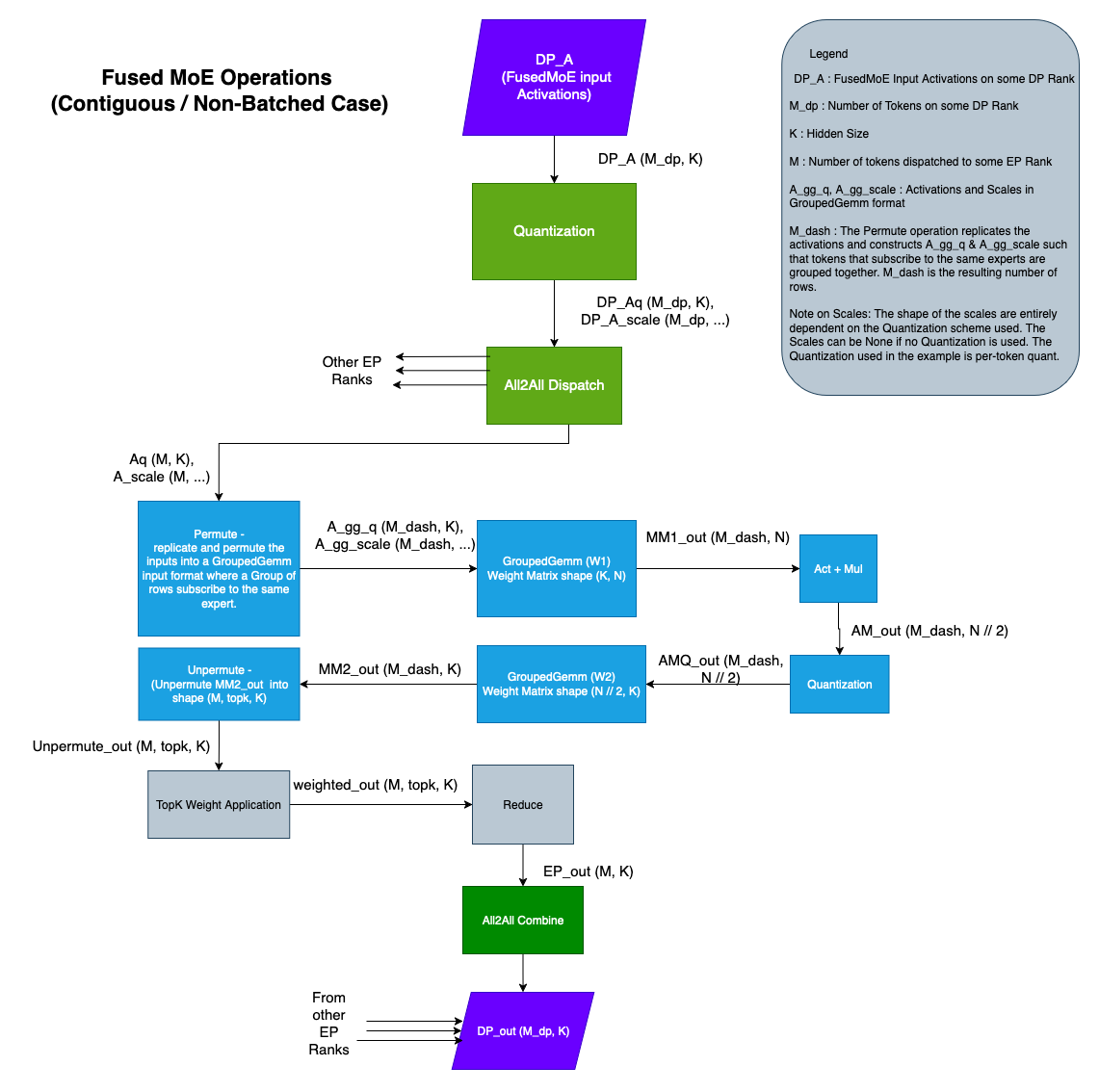
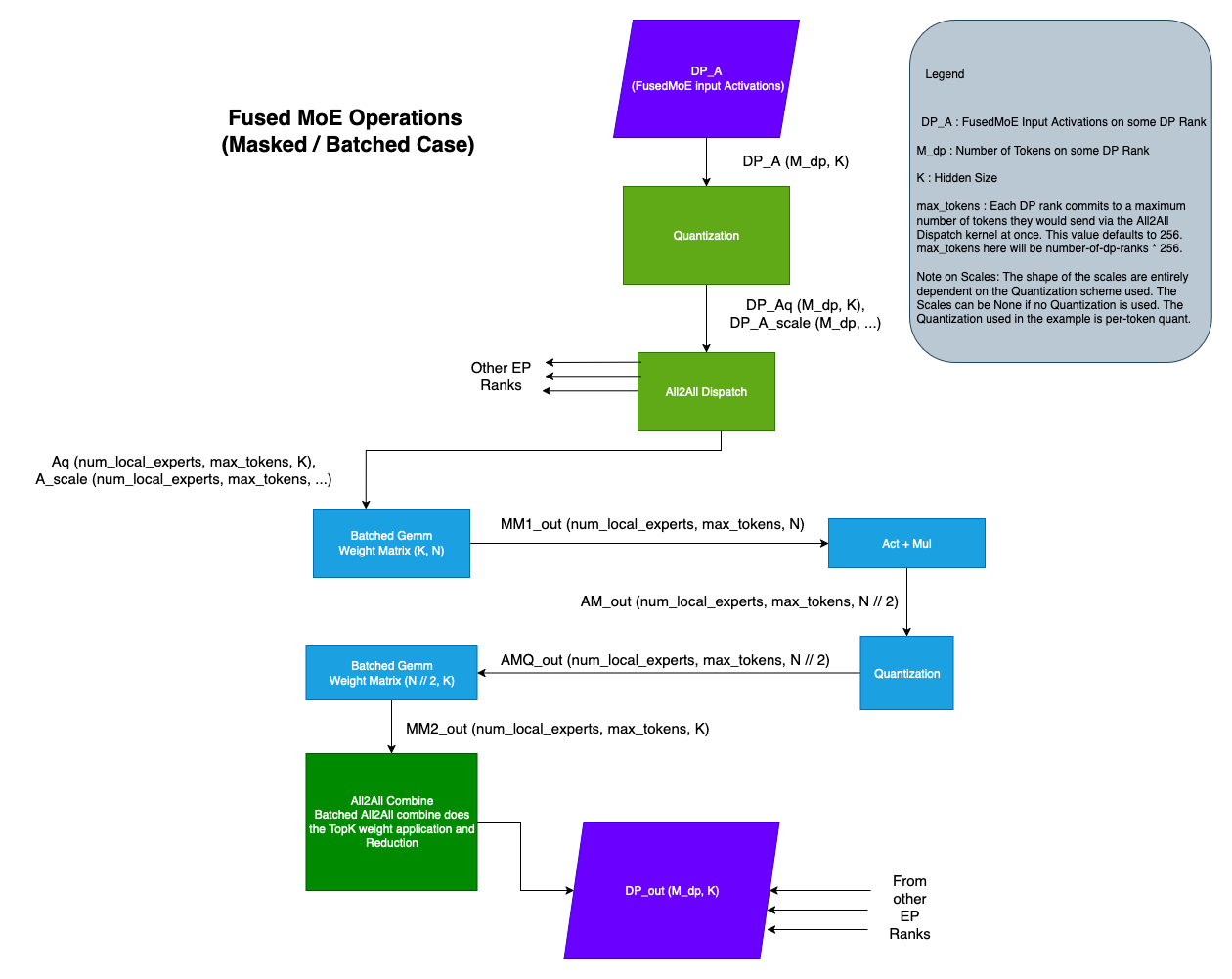
Note
Batched 与 Non-Batched 情况在操作上的主要区别在于 Permute / Unpermute 操作。其余操作保持不变。
Motivation¶
从图表中可以看出,存在大量操作,且每个操作都有多种实现方式。将这些操作组合成有效 FusedMoE 实现的方式数量迅速变得难以管理。Modular Kernel 框架通过将操作划分为逻辑组件来解决这一问题。这种宽泛的分类使组合数量变得可控,并避免代码重复。此外,该框架将 All2All Dispatch 和 Combine 实现与 FusedMoE 实现解耦,使其能够独立开发和测试。此外,Modular Kernel 框架为不同组件引入了抽象类,为未来的实现提供了明确定义的骨架。
本文档后续部分将聚焦于 Contiguous / Non-Batched 情况。Batched 情况的推导应较为直接。
ModularKernel Components¶
FusedMoEModularKernel 将 FusedMoE 操作划分为三个部分:
- TopKWeightAndReduce
- FusedMoEPrepareAndFinalize
- FusedMoEPermuteExpertsUnpermute
TopKWeightAndReduce¶
TopK 权重应用和归约操作发生在 Unpermute 操作之后、All2All Combine 之前。请注意,FusedMoEPermuteExpertsUnpermute 负责 Unpermute,而 FusedMoEPrepareAndFinalize 负责 All2All Combine。在 FusedMoEPermuteExpertsUnpermute 中执行 TopK 权重应用和归约具有优势,但某些实现选择在 FusedMoEPrepareAndFinalize 中执行。为支持这种灵活性,我们引入了 TopKWeightAndReduce 抽象类。
TopKWeightAndReduce 的实现请参见 此处。
FusedMoEPrepareAndFinalize::finalize() 方法接受一个 TopKWeightAndReduce 参数,并在方法内部调用该参数。
FusedMoEModularKernel 作为 FusedMoEPermuteExpertsUnpermute 和 FusedMoEPrepareAndFinalize 实现之间的桥梁,用于确定 TopK 权重应用和归约在何处执行。
FusedMoEPermuteExpertsUnpermute::finalize_weight_and_reduce_impl方法返回TopKWeightAndReduceNoOp,表示该实现自行执行权重应用和归约。FusedMoEPermuteExpertsUnpermute::finalize_weight_and_reduce_impl方法返回TopKWeightAndReduceContiguous/TopKWeightAndReduceNaiveBatched/TopKWeightAndReduceDelegate,表示该实现需要由FusedMoEPrepareAndFinalize::finalize()执行权重应用和归约。
FusedMoEPrepareAndFinalize¶
FusedMoEPrepareAndFinalize 抽象类公开了 prepare、prepare_no_receive 和 finalize 函数。
prepare 函数负责输入激活的量化和 All2All Dispatch。如果实现了 prepare_no_receive,则其功能类似于 prepare,但不会等待来自其他工作进程的结果,而是返回一个“接收器”回调函数,该函数必须被调用以等待工作进程的最终结果。并非所有 FusedMoEPrepareAndFinalize 类都需要支持此方法,但如果支持,可用于与初始 All-to-All 通信交错执行其他工作,例如交错共享专家与融合专家。
finalize 函数负责调用 All2All Combine。此外,finalize 函数可能执行也可能不执行 TopK 权重应用和归约(请参阅 TopKWeightAndReduce 部分)。
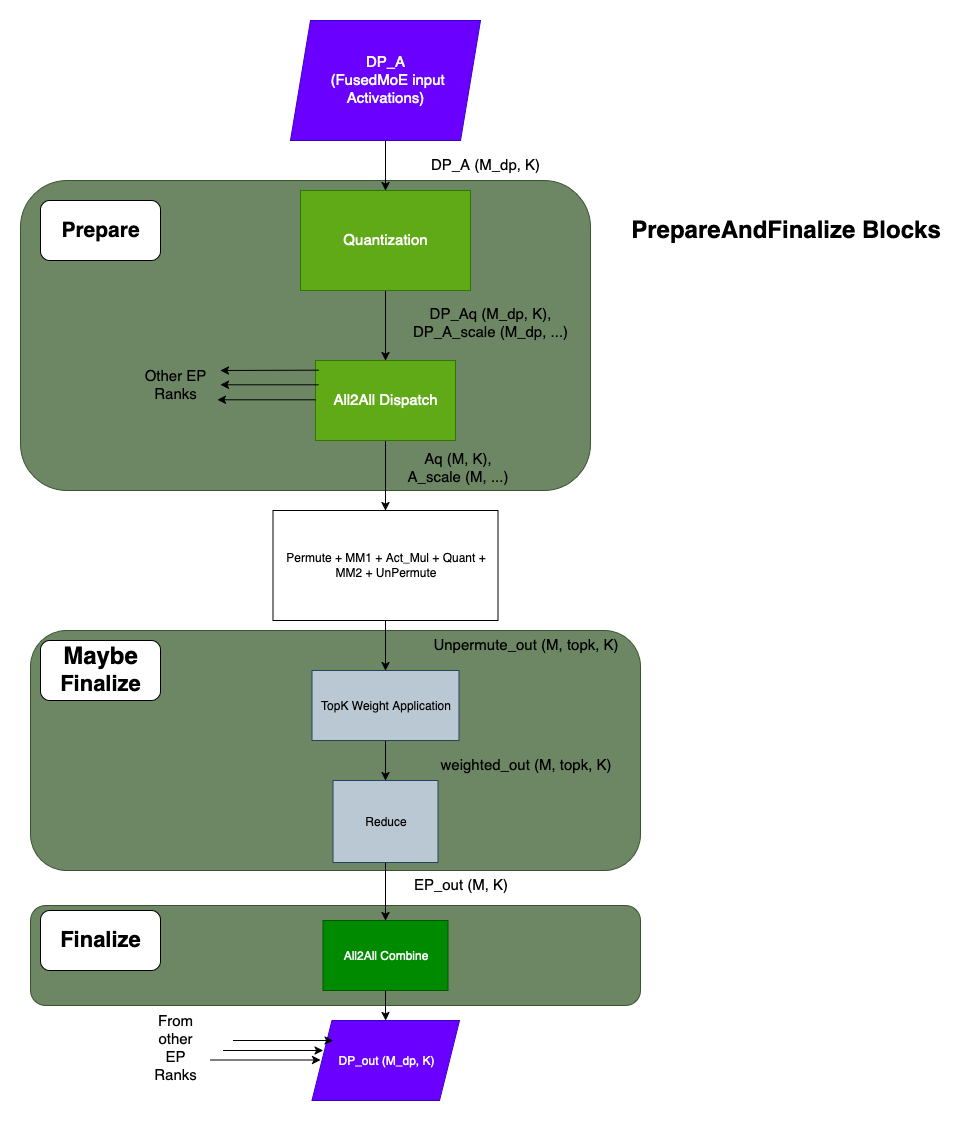
FusedMoEPermuteExpertsUnpermute¶
FusedMoEPermuteExpertsUnpermute 类是 MoE 核心操作的实现主体。FusedMoEPermuteExpertsUnpermute 抽象类公开了几个重要函数:
- apply()
- workspace_shapes()
- finalize_weight_and_reduce_impl()
apply()¶
apply 方法中,实现执行以下操作:
- Permute
- 与权重 W1 的矩阵乘法
- 激活函数 + 乘法
- 量化
- 与权重 W2 的矩阵乘法
- Unpermute
- 可选的 TopK 权重应用 + 归约
workspace_shapes()¶
核心 FusedMoE 实现会执行一系列操作。若为每个操作单独分配输出内存将效率低下。为此,实现需在 workspace_shapes() 方法中声明两个工作区形状、工作区数据类型以及 FusedMoE 输出形状。此信息用于在 FusedMoEModularKernel::forward() 中分配工作区张量和输出张量,并传递给 FusedMoEPermuteExpertsUnpermute::apply() 方法。这些工作区可作为实现中的中间缓冲区使用。
finalize_weight_and_reduce_impl()¶
有时在 FusedMoEPermuteExpertsUnpermute::apply() 内执行 TopK 权重应用和归约会更高效。示例请参见 此处。我们引入了 TopKWeightAndReduce 抽象类以支持此类实现。请参阅 TopKWeightAndReduce 部分。
FusedMoEPermuteExpertsUnpermute::finalize_weight_and_reduce_impl() 返回 TopKWeightAndReduce 对象,供 FusedMoEPrepareAndFinalize::finalize() 使用。
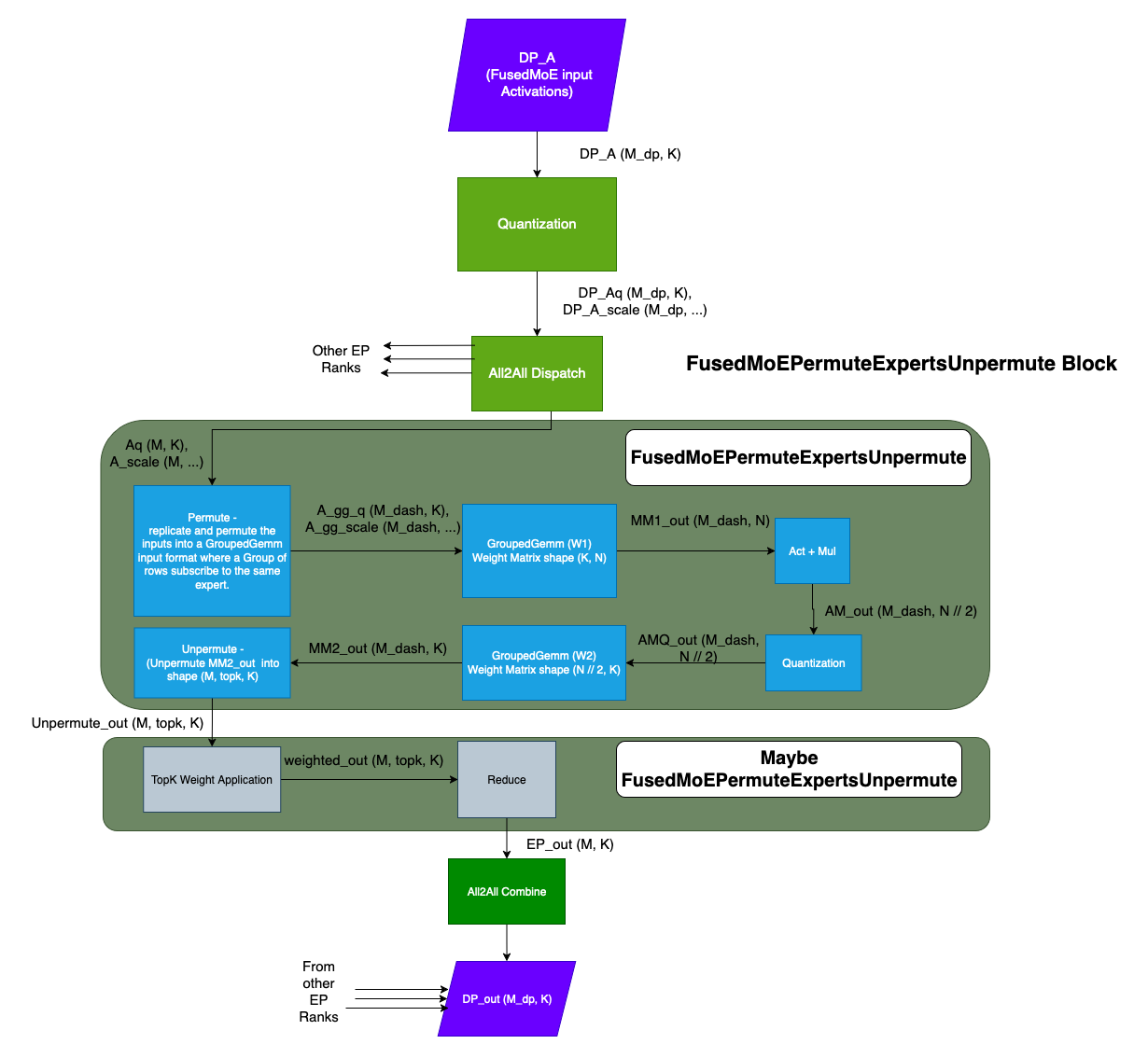
FusedMoEModularKernel¶
FusedMoEModularKernel 由 FusedMoEPrepareAndFinalize 和 FusedMoEPermuteExpertsUnpermute 对象组成。
FusedMoEModularKernel 的伪代码/草图如下:
class FusedMoEModularKernel:
def __init__(self,
prepare_finalize: FusedMoEPrepareAndFinalize,
fused_experts: FusedMoEPermuteExpertsUnpermute):
self.prepare_finalize = prepare_finalize
self.fused_experts = fused_experts
def forward(self, DP_A):
Aq, A_scale, _, _, _ = self.prepare_finalize.prepare(DP_A, ...)
workspace13_shape, workspace2_shape, _, _ = self.fused_experts.workspace_shapes(...)
# 分配工作区
workspace_13 = torch.empty(workspace13_shape, ...)
workspace_2 = torch.empty(workspace2_shape, ...)
# execute fused_experts
fe_out = self.fused_experts.apply(Aq, A_scale, workspace13, workspace2, ...)
# war_impl is an object of type TopKWeightAndReduceNoOp if the fused_experts implementations
# performs the TopK Weight Application and Reduction.
war_impl = self.fused_experts.finalize_weight_and_reduce_impl()
output = self.prepare_finalize.finalize(fe_out, war_impl,...)
return output
How-To¶
如何添加 FusedMoEPrepareAndFinalize 类型¶
通常,FusedMoEPrepareAndFinalize 类型由 All2All 分发与合并实现/内核支持。例如:
- PplxPrepareAndFinalize 类型由 Pplx All2All 内核支持,
- DeepEPHTPrepareAndFinalize 类型由 DeepEP 高吞吐 All2All 内核支持,以及
- DeepEPLLPrepareAndFinalize 类型由 DeepEP 低延迟 All2All 内核支持。
第一步:添加 All2All 管理器¶
All2All 管理器的目的是设置 All2All 内核实现。FusedMoEPrepareAndFinalize 实现通常会从 All2All 管理器中获取内核实现的“句柄”,以调用分发和合并函数。请参阅此处的 All2All 管理器实现 here。
第二步:添加 FusedMoEPrepareAndFinalize 类型¶
本节介绍 FusedMoEPrepareAndFinalize 抽象类所暴露的各个函数的意义。
FusedMoEPrepareAndFinalize::prepare():该 prepare 方法实现量化和 All2All 分发。通常会调用相关 All2All 管理器中的分发函数。
FusedMoEPrepareAndFinalize::has_prepare_no_receive():指示该子类是否实现了 prepare_no_receive。默认值为 False。
FusedMoEPrepareAndFinalize::prepare_no_receive():该 prepare_no_receive 方法实现量化和 All2All 分发,但不会等待分发操作的结果,而是返回一个可调用的 thunk 以等待最终结果。通常会调用相关 All2All 管理器中的分发函数。
FusedMoEPrepareAndFinalize::finalize():可能执行 TopK 权重应用和归约以及 All2All 合并。通常会调用相关 All2AllManager 的合并函数。
FusedMoEPrepareAndFinalize::activation_format():如果 prepare 方法的输出(即 All2All 分发)是批处理的,则返回 FusedMoEActivationFormat.BatchedExperts;否则返回 FusedMoEActivationFormat.Standard。
FusedMoEPrepareAndFinalize::topk_indices_dtype():TopK 索引的数据类型。某些 All2All 内核对 TopK 索引的数据类型有严格要求。此要求会被传递给 FusedMoe::select_experts 函数以确保其被遵守。如果没有严格要求,则返回 None。
FusedMoEPrepareAndFinalize::max_num_tokens_per_rank():一次提交到 All2All 分发的最大 token 数量。
FusedMoEPrepareAndFinalize::num_dispatchers():分发单元的总数。该值决定了分发输出的大小。分发输出的形状为 (num_local_experts, max_num_tokens, K),其中 max_num_tokens = num_dispatchers() * max_num_tokens_per_rank()。
建议选择一个与您的 All2All 实现密切匹配的现有 FusedMoEPrepareAndFinalize 实现,并将其作为参考。
如何添加 FusedMoEPermuteExpertsUnpermute 类型¶
FusedMoEPermuteExpertsUnpermute 执行 FusedMoE 操作的核心部分。抽象类所暴露的各个函数及其意义如下:
FusedMoEPermuteExpertsUnpermute::activation_formats():返回支持的输入和输出激活格式,即连续/批处理格式。
FusedMoEPermuteExpertsUnpermute::supports_chunking():如果实现支持分块,则返回 True。通常,输入 FusedMoEActivationFormat.Standard 的实现支持分块,而 FusedMoEActivationFormat.BatchedExperts 不支持。
FusedMoEPermuteExpertsUnpermute::supports_expert_map():如果实现支持专家映射,则返回 True。
FusedMoEPermuteExpertsUnpermute::workspace_shapes() / FusedMoEPermuteExpertsUnpermute::finalize_weight_and_reduce_impl / FusedMoEPermuteExpertsUnpermute::apply:请参阅上述 FusedMoEPermuteExpertsUnpermute 部分。
FusedMoEModularKernel 初始化¶
FusedMoEMethodBase 类有三个方法共同负责创建 FusedMoEModularKernel 对象,分别是:
- maybe_make_prepare_finalize,
- select_gemm_impl,以及
- init_prepare_finalize
maybe_make_prepare_finalize¶
maybe_make_prepare_finalize 方法负责在适当的情况下(例如启用 EP + DP 时)根据当前的 All2All 后端构造 FusedMoEPrepareAndFinalize 的实例。基类方法当前为 EP+DP 情况构造所有 FusedMoEPrepareAndFinalize 对象。派生类可以重写此方法以针对不同场景构造 prepare/finalize 对象,例如 ModelOptNvFp4FusedMoE 可以为 EP+TP 情况构造 FlashInferCutlassMoEPrepareAndFinalize。 请参阅以下实现:
ModelOptNvFp4FusedMoE
select_gemm_impl¶
select_gemm_impl 方法在基类中未定义。派生类有责任实现一个方法来构造有效且适当的 FusedMoEPermuteExpertsUnpermute 对象。 请参阅以下实现:
UnquantizedFusedMoEMethodCompressedTensorsW8A8Fp8MoEMethodCompressedTensorsW8A8Fp8MoECutlassMethodFp8MoEMethodModelOptNvFp4FusedMoE派生类。
init_prepare_finalize¶
根据输入和环境设置,init_prepare_finalize 方法创建适当的 FusedMoEPrepareAndFinalize 对象。该方法随后查询 select_gemm_impl 以获取适当的 FusedMoEPermuteExpertsUnpermute 对象,并构建 FusedMoEModularKernel 对象。
请查看 init_prepare_finalize。 重要:FusedMoEMethodBase 的派生类在其 apply 方法中使用 FusedMoEMethodBase::fused_experts 对象。当设置允许构造有效的 FusedMoEModularKernel 对象时,我们会用它覆盖 FusedMoEMethodBase::fused_experts。这实质上使派生类与所使用的 FusedMoE 实现无关。
如何进行单元测试¶
我们在 test_modular_kernel_combinations.py 中提供了 FusedMoEModularKernel 的单元测试。
该单元测试遍历所有 FusedMoEPrepareAndFinalize 和 FusedMoEPremuteExpertsUnpermute 类型的组合,如果它们兼容,则运行一些正确性测试。 如果您添加了 FusedMoEPrepareAndFinalize / FusedMoEPermuteExpertsUnpermute 实现,
- 将实现类型添加到 mk_objects.py 中的
MK_ALL_PREPARE_FINALIZE_TYPES和MK_FUSED_EXPERT_TYPES。 - 更新 /tests/kernels/moe/modular_kernel_tools/common.py 中的
Config::is_batched_prepare_finalize()、Config::is_batched_fused_experts()、Config::is_standard_fused_experts()、Config::is_fe_16bit_supported()、Config::is_fe_fp8_supported()、Config::is_fe_block_fp8_supported()、Config::is_fe_supports_chunking()方法。
执行这些操作后,新的实现将被添加到测试套件中。
如何检查 FusedMoEPrepareAndFinalize 与 FusedMoEPermuteExpertsUnpermute 的兼容性¶
单元测试文件 test_modular_kernel_combinations.py 也可作为独立脚本执行。
示例:python3 -m tests.kernels.moe.test_modular_kernel_combinations --pf-type PplxPrepareAndFinalize --experts-type BatchedTritonExperts
作为副作用,该脚本可用于测试 FusedMoEPrepareAndFinalize 与 FusedMoEPermuteExpertsUnpermute 的兼容性。当使用不兼容的类型调用时,脚本将报错。
如何进行性能分析¶
请查看 profile_modular_kernel.py
该脚本可用于为任意兼容的 FusedMoEPrepareAndFinalize 和 FusedMoEPermuteExpertsUnpermute 类型生成单次 FusedMoEModularKernel::forward() 调用的 Torch 追踪。
示例:python3 -m tests.kernels.moe.modular_kernel_tools.profile_modular_kernel --pf-type PplxPrepareAndFinalize --experts-type BatchedTritonExperts
FusedMoEPrepareAndFinalize 实现¶
有关所有可用的模块化 prepare 和 finalize 子类列表,请参阅 Fused MoE Kernel features。
FusedMoEPermuteExpertsUnpermute¶
有关所有可用的模块化专家列表,请参阅 Fused MoE Kernel features。