如何调试 vLLM-torch.compile 集成¶
简要说明:
- 使用 tlparse 获取 torch.compile 日志。在提交 bug 报告或寻求支持时,请包含这些日志。
- vLLM-torch.compile 集成由多个部分组成。vLLM 提供了标志来分别关闭每个部分:
| 在线标志 | 离线标志 | 结果 |
|---|---|---|
| --enforce-eager | enforce_eager=True | 关闭 torch.compile 和 CUDAGraphs |
| -cc.mode=0 | mode=CompilationMode.NONE | 仅关闭 torch.compile |
| -cc.cudagraph_mode=NONE | compilation_config=CompilationConfig(cudagraph_mode=CUDAGraphMode.NONE) | 仅关闭 CUDAGraphs |
| -cc.backend=eager | compilation_config=CompilationConfig(backend='eager') | 关闭 TorchInductor |
vLLM-torch.compile 概述¶
为了提高性能,vLLM 利用 torch.compile 和 CUDAGraphs 来加速运行。 torch.compile 为 PyTorch 代码生成优化的内核,而 CUDAGraphs 则消除了开销。 值得注意的是,vLLM-compile 并非 torch.compile,而是使用 PyTorch Compile 内部 API 构建的自定义编译器。
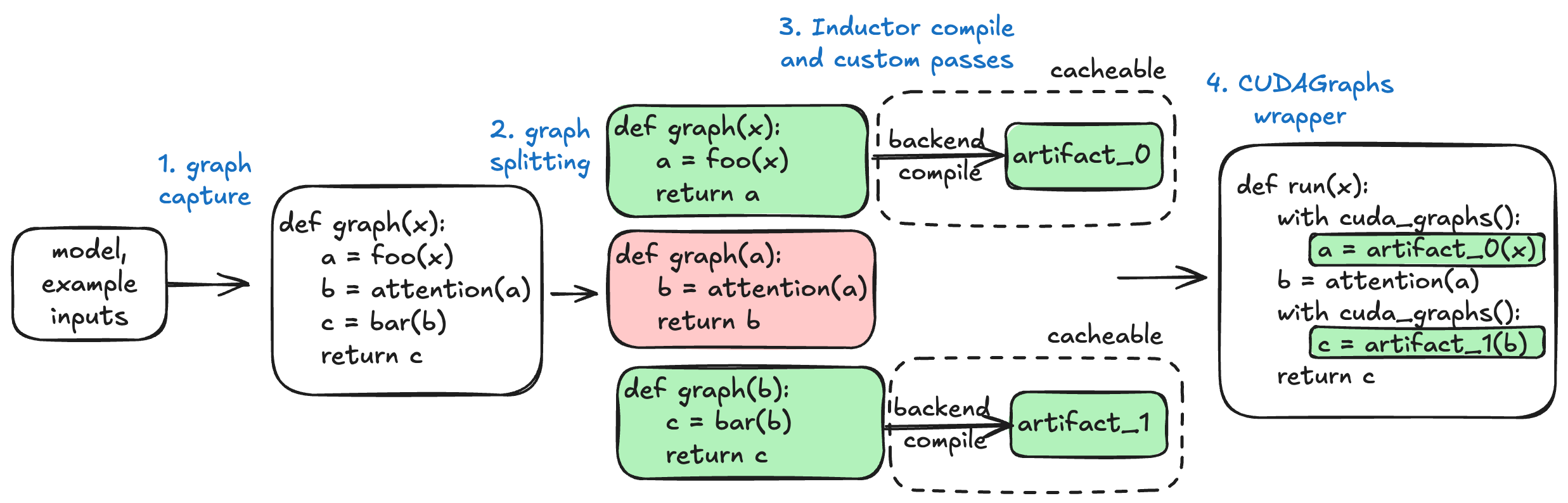
- 给定一个模型,我们通过 TorchDynamo 进行全图捕获,该图在批处理大小(token 数量)上是动态的。
- 然后,vLLM 可选择性地拆分和/或特化此图,并使用 TorchInductor 将每个图编译为编译后的工件。 此步骤可能使用 vLLM 自定义的 Inductor 传递来进一步优化图。
- 编译后的工件保存到 vLLM 的编译缓存中,以便将来加载。
- vLLM 应用 CUDAGraphs 来减少 CPU 开销。
这四个步骤中的任何一个都可能出现问题。当出现问题时,请尝试隔离出问题的子系统——这将允许您关闭最少数量的功能,以保持可靠性目标,同时将性能影响降至最低,并且当您提交 bug 报告时,也能帮助我们(vLLM)。
有关设计的更多详细信息,请参阅以下资源:
使用 tlparse¶
使用 tlparse 查看 torch.compile 日志。这些日志显示了编译过程的所有阶段,包括 torch.compile 生成的融合内核。
安装 tlparse:
要启用 torch.compile 日志,可以设置环境变量 TORCH_TRACE=<dir>。在跟踪期间,将在该目录中为每个 rank 创建一个文件,每个文件包含编译期间的工件。如果可以,我们建议您在提交 bug 报告时一并发送这些日志文件——它们非常有帮助。
用法(离线推理)
用法(服务)
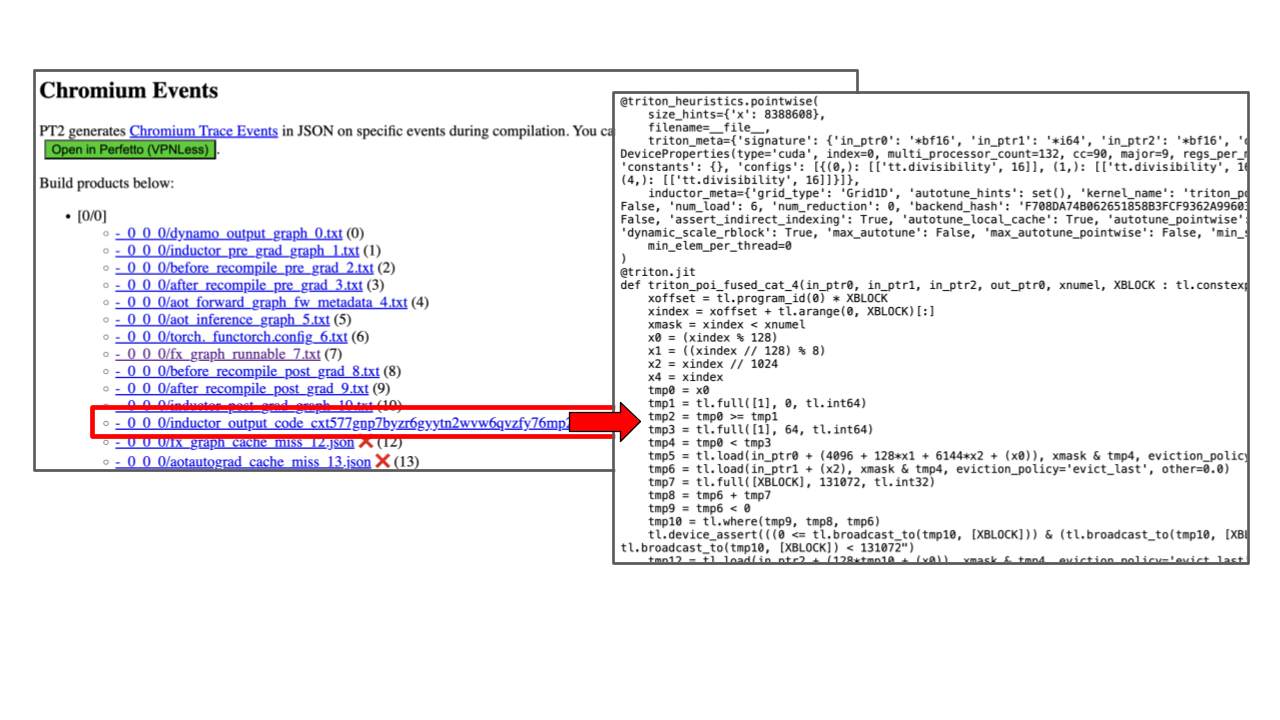
给定其中一个日志文件,tlparse 命令会输出一些 HTML 文件(例如 ./tl_out/index.html)。打开它以查看日志。它看起来类似于以下内容:
关闭 vLLM-torch.compile 集成¶
传递 --enforce-eager 以关闭 vLLM-torch.compile 集成,并完全在 eager 模式下运行。这包括关闭 CUDAGraphs。
要仅关闭 torch.compile,请将 mode = NONE 传递给编译配置。(-cc 是 --compilation_config 的缩写):
# 离线
from vllm.config.compilation import CompilationConfig, CompilationMode
LLM(model, compilation_config=CompilationConfig(mode=CompilationMode.NONE))
要仅关闭 CUDAGraphs,请传递 cudagraph_mode = NONE:
# 离线
from vllm.config.compilation import CompilationConfig, CUDAGraphMode
LLM(model, compilation_config=CompilationConfig(cudagraph_mode=CUDAGraphMode.NONE))
调试 TorchDynamo¶
vLLM 要求模型代码可通过 TorchDynamo(torch.compile 的前端)捕获为完整图。TorchDynamo 不支持所有 Python 功能。如果它不支持某个功能(在 fullgraph 模式下),则会报错(这有时被称为图中断)。
如果遇到图中断,请向 pytorch/pytorch 提交问题,以便 PyTorch 开发人员优先处理。然后,请尽力重写代码以避免图中断。更多信息,请参阅此 Dynamo 指南。
调试动态形状全图捕获¶
vLLM 要求模型的前向传递可被捕获为一个在批处理大小(即 token 数量)上动态的图。它(默认情况下)将此图编译为一个工件,并将此工件用于所有批处理大小。
如果您的代码无法通过动态形状捕获,您可能会看到静默错误、明显错误或 CUDA 非法内存访问。例如,以下内容无法被捕获为单个图:
这个问题很容易诊断。使用 tlparse 并点击 compilation_metrics:它会告诉您批处理大小的符号约束。如果存在任何限制批处理大小的约束,那么我们就遇到了问题。

为避免此问题,请:
- 避免基于 token 数量进行分支
- 将分支逻辑包装到自定义操作符中。TorchDynamo 不会跟踪自定义操作符。
调试约束违规和动态形状守卫问题¶
动态形状守卫是 Dynamo 守卫的一个特定类别。它们是 torch.compile 附加到动态维度(例如 seq_len)上的约束,以确保编译后的工件保持有效。当框架代码、自定义传递或用户代码基于动态形状值进行分支时,通常会出现这些守卫。
示例:
这会创建一个守卫 x > 10 或 x <= 10,具体取决于跟踪的路径。
vLLM 的假设: vLLM 假设 torch.compile 添加的所有守卫都可以安全地删除,并且不会将编译后的图约束到特定的输入形状。当此假设被违反时,可能会导致用户需要调试的问题。表明此假设被违反的一些副作用是运行时错误或 ConstraintViolationErrors。
如果动态形状被约束为单个值,则会抛出 ConstraintViolationErrors。如果您遇到约束违规错误或怀疑动态形状守卫被错误地添加,可以使用更严格的动态形状模式来帮助调试问题:
# 在线 - 使用 unbacked 模式
vllm serve meta-llama/Llama-3.2-1B -cc.dynamic_shapes_config.type=unbacked
# 在线 - 使用 backed_size_oblivious 模式
vllm serve meta-llama/Llama-3.2-1B -cc.dynamic_shapes_config.type=backed_size_oblivious
# 离线 - 使用 unbacked 模式
from vllm.config.compilation import CompilationConfig, DynamicShapesConfig, DynamicShapesType
LLM(model, compilation_config=CompilationConfig(
dynamic_shapes_config=DynamicShapesConfig(type=DynamicShapesType.UNBACKED)
))
# 离线 - 使用 backed_size_oblivious 模式
from vllm.config.compilation import CompilationConfig, DynamicShapesConfig, DynamicShapesType
LLM(model, compilation_config=CompilationConfig(
dynamic_shapes_config=DynamicShapesConfig(type=DynamicShapesType.BACKED_SIZE_OBLIVIOUS)
))
这些模式更严格,可以减少或消除对动态形状守卫的需求,从而有助于隔离问题:
unbacked:使用无后备支持的符号整数(symints),不允许设置守卫(guards),从而更容易识别守卫被错误添加的位置。backed_size_oblivious:使用一种更严格的守卫模式。
有关动态形状模式的更多详细信息,请参阅动态形状和 vLLM 守卫丢弃。
打印守卫信息¶
要查看编译期间添加的所有守卫,可以使用 TORCH_LOGS=+dynamic:
在日志中查找 [guard added],以查看守卫被添加的位置。这有助于识别哪些操作导致了守卫被错误添加。
调试 TorchInductor¶
TorchInductor 接收一个被捕获的计算图,然后将其编译为一些 Python 代码,这些代码可能会调用 1 个或多个 Triton 内核。在极少数(但不幸)的情况下,它可能会生成一个不正确的 Triton 内核。这可能表现为静默的错误、CUDA 非法内存访问,或明显的错误。
要调试是否是 TorchInductor 的问题,可以通过在编译配置中传递 backend='eager' 来禁用它:
如果问题确实出在 Inductor 上,请向 PyTorch 提交 bug。如果你愿意深入调试,可以使用 tlparse 定位 Inductor 输出代码中的 Triton 内核并进行调试。
你也可以使用 TORCH_LOGS=output_code <command> 来打印 Inductor 的输出代码。
可编辑的 TorchInductor 代码¶
你可以通过设置 VLLM_COMPILE_CACHE_SAVE_FORMAT=unpacked 或传递 -cc.compile_cache_save_format=unpacked 来编辑运行的 TorchInductor 代码。默认值为 binary,这意味着代码不可编辑。
这是一项非常有用的技术:你可以在输出代码中设置断点(例如 torch.distributed.breakpoint())和打印语句。
调试 vLLM-compile 缓存¶
vLLM 为 torch.compile 构建了自己的缓存机制。其核心思想是:编译产物只需编译一次,之后便可重复使用。这是构建在 torch.compile 的编译器缓存之上的一层封装。
虽然 torch.compile 的编译器缓存非常稳定,但遗憾的是,vLLM 的编译器缓存并不总是正确的。你可以通过设置 VLLM_DISABLE_COMPILE_CACHE=1 来禁用它。
你也可以手动清除此缓存:
- 使用
rm -rf ~/.cache/vllm删除 vLLM 的编译缓存(查看日志以确认路径是否已更改) - 使用
rm -rf /tmp/torchinductor_$(whoami)删除 torch.compile 的内置缓存
vLLM 的缓存是一个从缓存键到已编译产物的映射。vLLM 通过组合多个因素(例如配置标志和模型名称)来计算缓存键。如果 vLLM 的编译缓存出错,通常意味着某个因素缺失。请参考此示例,了解 vLLM 如何计算部分缓存键。
调试 CUDAGraphs¶
CUDAGraphs 是一项允许你执行以下操作的功能:
- 将一个调用 1 个或多个 CUDA 内核的可调用对象捕获为 CUDAGraph
- 重放该 CUDAGraph
被捕获的 CUDAGraph 包含了捕获过程中使用的所有内存。CUDAGraph 的重放会精确地读写相同的内存区域。
这带来了一些限制:
- 若要在新数据上使用 CUDAGraphs,你需要将数据复制到 CUDAGraph 正在读取的缓冲区中
- CUDAGraphs 仅捕获 CUDA 内核,不会捕获在 CPU 上执行的工作
vLLM 使用原生的 CUDAGraphs API,如果使用不当,可能会不安全。
要仅关闭 CUDAGraphs,请传递 cudagraph_mode = NONE: