CUDA 图表¶
本文档介绍 vLLM v1 中新增的 CUDA 图表模式,超越了之前的 torch.compile 集成。简而言之,我们:
- 添加了灵活的
cudagraph_mode配置 - 使完整的 CUDA 图表支持与编译正交
- 引入了 CUDA 图表调度器作为中央控制器,自动为每个批次选择期望的运行时模式和 CUDA 图表
在本文档中,我们将讨论以下内容:
Note
在本文档中,我们将纯解码(max_query_len=1)或推测解码(max_query_len=1+num_spec_tokens)称为均匀解码批次,相反则是非均匀批次(即预填充或混合预填充-解码批次)。
Note
以下内容主要基于 Pull Request #20059 的最新提交。
动机¶
最初的分段编译是为了允许分段 cudagraph 捕获,排除不支持 cudagraph 的操作(主要是注意力机制)。这在保持与所有注意力后端兼容的同时,允许从 cudagraph 获得一些加速。我们后来通过不进行分段编译,添加了“完整 cudagraphs”的支持,以便在注意力机制支持 cudagraph 时进一步降低延迟。然而,编译与 cudagraph 捕获之间的紧密耦合导致了一种非此即彼的体验,灵活性极低。许多注意力后端也不支持统一的“完整”CUDA 图表捕获(例如,目前只有 FlashAttention 3 支持),或者只支持在纯解码批次中使用 CUDA 图表(例如 Flashinfer、FlashMLA 和 Mamba 等)。这导致了令人困惑的性能/兼容性权衡、不一致的 CUDA 图表支持以及日益复杂的代码结构。
这促使我们寻求一种更细粒度的 CUDA 图表解决方案,具有以下特性:
- 明确区分预填充/混合批次或(均匀-)解码批次的 CUDA 图表,并分别捕获它们。
- 将 CUDAGraph 捕获逻辑与编译分离(尽可能),以实现功能正交,这意味着:
- 使用同一编译图捕获分段和完整的 cudagraph,
- 在无需编译的情况下进行完整 cudagraph 捕获。
- 根据批次组成在完整 cudagraph 和分段 cudagraph 之间运行时进行调度。
- 集中控制 CUDAGraph 行为,以减少代码复杂性并允许更多可扩展性。
这些特性为所有类型的启动/性能权衡和功能支持提供了最大灵活性的 cudagraph 捕获和编译。
CudagraphModes¶
CUDAGraphMode 是您在 CompilationConfig.cudagraph_mode 中调节的唯一旋钮:
NONE— 关闭 CUDA 图表。适合调试。PIECEWISE— 单模式策略(过去的默认值)。它是最灵活的:注意力或其他不兼容 CUDA 图表的操作保持急切执行,其余部分进入 CUDA 图表。需要分段编译。FULL— 单模式策略,仅对非均匀批次捕获完整 CUDA 图表,然后均匀解码批次重用相同 batch_size 的非均匀批次的 CUDA 图表,因为它们兼容;适合小模型或小提示的工作负载。FULL_DECODE_ONLY— 均匀解码的完整 CUDA 图表,预填充/混合等无 cudagraph;适合 P/D 设置中的解码实例,其中预填充不太重要,这样我们可以节省PIECEWISECUDA 图表所需的内存。FULL_AND_PIECEWISE—(默认模式)均匀解码的完整 CUDA 图表,其他使用分段 CUDA 图表;通常性能最佳,特别是对于小模型或 MoE 的低延迟,但也需要最多内存且捕获耗时最长。
默认值:如果您使用 v1 的分段编译,我们默认使用 FULL_AND_PIECEWISE 以获得更好性能(对于池化模型,仍为 PIECEWISE)。否则,例如当分段编译不可用时,我们默认使用 NONE。
虽然 NONE、PIECEWISE 和 FULL 是单模式配置,分别等同于过去的急切执行、分段 CUDA 图表和完整 CUDA 图表实现,但 FULL_DECODE_ONLY 和 FULL_AND_PIECEWISE 是新增的双模式配置,需要根据运行时批次动态调度以在具体运行时模式之间切换。
Note
此处,单模式 NONE、PIECEWISE 和 FULL 被视为 CUDA 图表调度的运行时模式。如果使用双模式,调度器将始终根据批次组成调度到其成员模式之一(如果无合适的 CUDA 图表可用,还包括潜在的 NONE)。
虽然级联注意力不兼容 cudagraph,但现在与所有可能的 cudagraph 模式配置兼容。如果批次使用级联注意力,只要可用就始终调度到 PIECEWISE 模式(否则为 NONE)。
Note
并非所有 CUDA 图表模式都兼容每个注意力后端。我们自动“降级”模式到最接近的支持模式。例如,如果后端仅支持纯解码/均匀批次的 CUDA 图表,我们会在启用分段编译时将 FULL 转换为 FULL_AND_PIECEWISE,否则转换为 FULL_DECODE_ONLY。
详细设计¶
概述¶
新的 CUDA 图表逻辑构建在分段编译之上,支持双 CUDA 图表运行时模式切换。该系统包含以下核心组件:
- CUDAGraphWrapper:包装器,处理对包装可调用对象的 CUDAGraph 捕获和重放
- CudagraphDispatcher:中央控制器,包含 CUDA 图表的单一事实来源并处理它们之间的调度
- CUDAGraphMode:枚举,描述支持的和运行时模式(如上所述)
- BatchDescriptor:作为运行时批次的唯一表示,用于调度
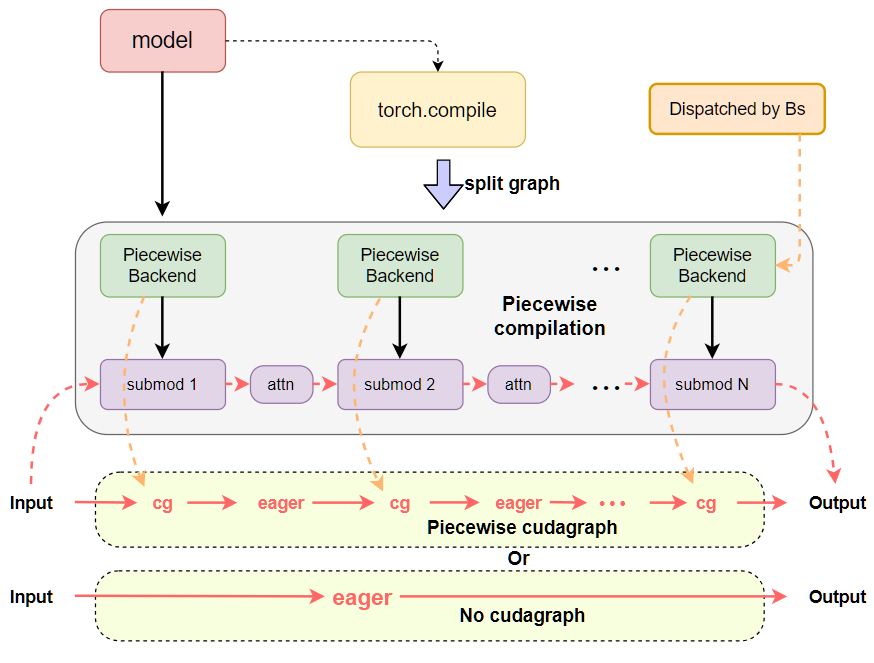
请参阅以下图表,快速比较之前和当前使用 inductor 编译的 CUDA 图表设计模式。我们可以看到,之前 CUDA 图表逻辑和编译逻辑紧密耦合在 vllm 的 PiecewiseBackend 中,CUDA 图表通过 batch_size 闲置地隐式调度。现在 CUDA 图表逻辑被分离到 CUDAGraphWrapper 类中,负责完整和分段 CUDA 图表功能,调度则显式通过运行时模式加上 BatchDescriptor 作为调度键,通过 CudagraphDispatcher 进行。
之前:
之后:
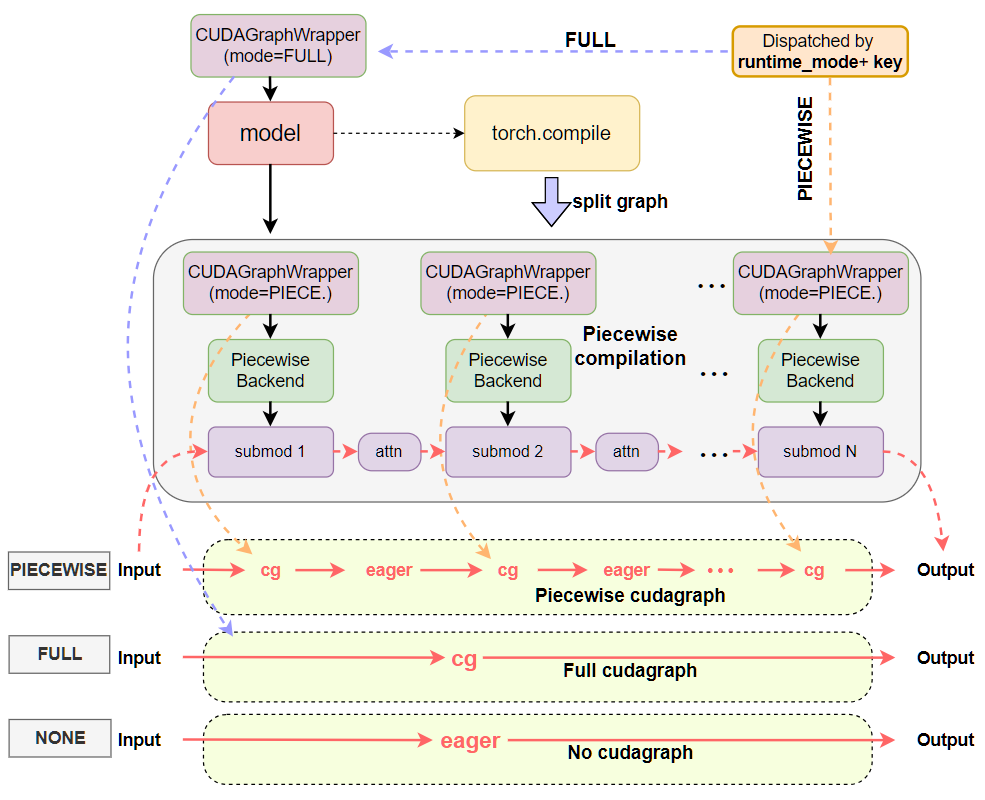
BatchDescriptor¶
BatchDescriptor 是 ForwardContext 中的组件,与 CUDA 图表运行时模式并列,作为运行时调度键的核心结构。原型如下:
class BatchDescriptor(NamedTuple):
num_tokens: int
num_reqs: int
uniform: bool = False
has_lora: bool = False
其中 num_tokens 可以是填充后的 token 长度,uniform 表示所有请求是否具有相同的查询长度。许多注意力后端仅在批次为均匀时支持完整 cudagraph;纯解码批次是均匀的,但查询长度可能不是 1(即 num_tokens == num_reqs),这在 spec-decode 的验证阶段中出现,此时“解码”批次的查询长度为 1+num_spec_tokens。
该结构的目标是用尽可能少的项目唯一标识一个(填充的)批次,对应于一个 CUDA 图表项。
Note
BatchDescriptor 的原型可能会在将来扩展以支持更通用的情况,例如包含更多项目,如 uniform_query_len,以支持多种不同的均匀解码长度设置 ( Pull Request #23679),或其他修改以支持对输入不一定是 token 长度感知的模型的 CUDA 图(例如,某些多模态输入)。
CudagraphDispatcher¶
CudagraphDispatcher 负责维护两组有效的分发密钥,一组用于 FULL 运行时模式,另一组用于 PIECEWISE 运行时模式,并在执行模型前向传播之前分发正确的运行时模式和分发密钥。它会接收初始密钥(用于填充输入的粗略 batch_descriptor),并返回所选的运行时模式和最终的 batch_descriptor,然后通过前向上下文告知 CUDAGraphWarpper 实例该决策。请注意,CudagraphDispatcher 是可用 CUDA 图密钥的唯一权威来源,CUDAGraphWrapper 实例可以盲目信任前向上下文来决定分发到哪个 CUDA 图。这让我们能够简化包装器代码,并将逻辑集中到分发器中。
分发密钥通过分发器的 initialize_cudagraph_keys 方法初始化,该方法在所有可能的注意力后端初始化完成后由 gpu_model_runner 调用。在这里,我们将来可以实现更复杂的逻辑,以“准备”各种 CUDA 图组合。目前,我们只是根据编译配置中 cudagraph_mode 的 decode_mode/mixed_mode 以及 cudagraph_capture_sizes 的有效组合来追加可用的密钥。
分发代码如下:
batch_descriptor=BatchDescriptor(num_tokens=num_input_tokens, uniform_decode=...)
runtime_mode, batch_descriptor = cudagraphdispatcher.dispatch(batch_descriptor)
# 执行
with set_forward_context(
...,
cudagraph_runtime_mode=runtime_mode,
batch_descriptor=batch_descriptor,
):
output = self.model(...)
在 dispatch() 方法内部,分发器会搜索合适的 CUDA 图运行时模式和现有的分发密钥以返回结果。我们基本上按照以下优先级搜索现有密钥:FULL>PIECEWISE>None。如果分发密钥不存在,则默认返回 NONE 模式以进行急切执行。具体实现可以参见 此处。
以下是模型执行器在运行时的工作流程简化图: 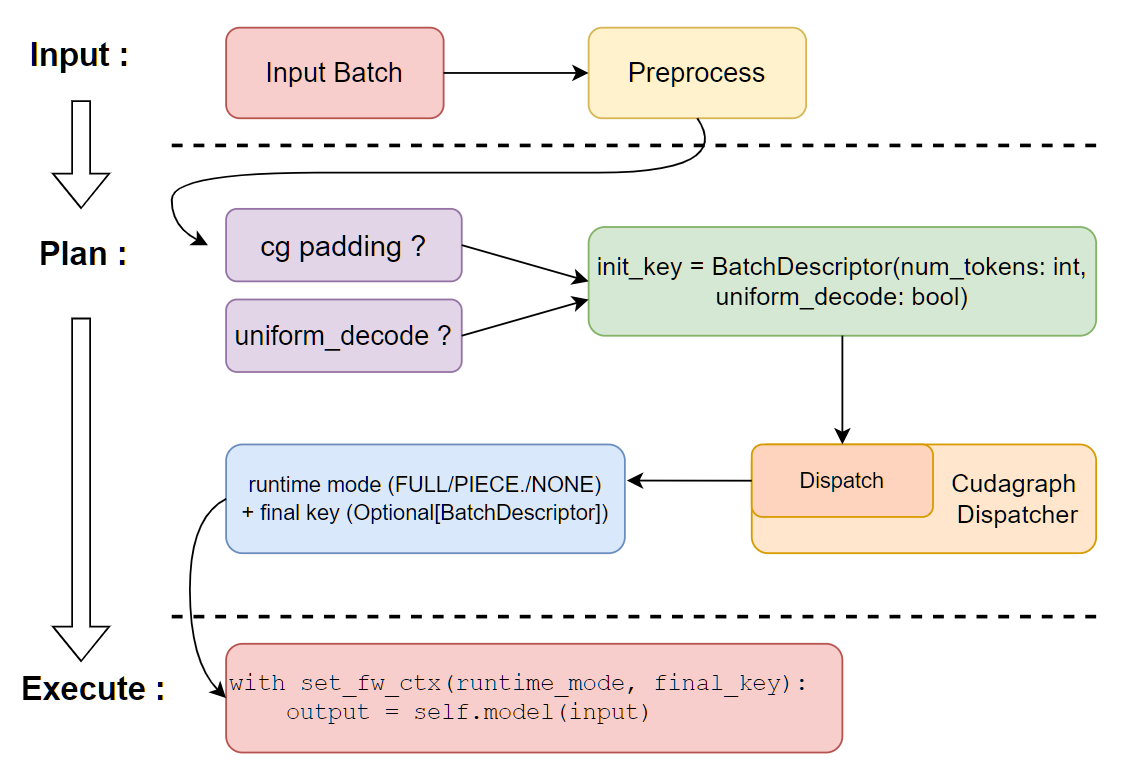
CUDAGraphWrapper¶
CUDAGraphWrapper 实例包装一个可运行对象,并简单地模仿可运行对象,附加了 CUDA 图能力。每个包装器实例绑定到特定的 runtime_mode,该模式仅限于 PIECEWISE 和 FULL 模式,并负责捕获/重放以及传递(直接调用)可运行对象。在运行时,每个包装器会:
- 从全局前向上下文中检查 runtime_mode 和 batch_descriptor(分发密钥)。
- 如果 runtime_mode 是
NONE或者 runtime_mode 与包装器的模式不匹配,则直接调用可运行对象。 - 否则,即 runtime_mode 与包装器的模式匹配,包装器将执行 CUDA 图捕获(如果密钥不存在,则创建新条目并缓存它)或重放(如果密钥存在于缓存中)。
上述步骤基于 CUDA 图包装器直接信任前向上下文内容(由分发器控制)的假设。这让我们能够简化并集中逻辑,降低复杂性以及包装器与分发器之间状态不匹配的风险。它还允许在 FULL 和 PIECEWISE 运行时模式下重用包装器类。具体实现请参见 此处。
嵌套包装器设计¶
使完整 CUDA 图和分段 CUDA 图共存且兼容的核心机制是嵌套 CUDA 图包装器设计,它基于仅包含单个分段 FX 图的分段编译构建。我们为完整 CUDA 图功能在外层整个模型上包装一个 FULL 模式包装器;同时,每个分段后端在编译内部通过一个 PIECEWISE 模式包装器进行包装。
下图流程图应能清楚地描述其工作原理。 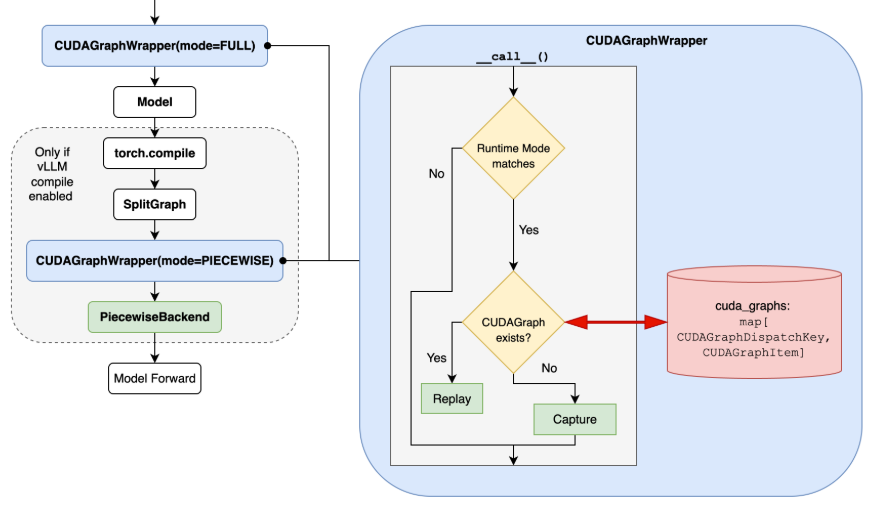
因此,对于 FULL 运行时模式,由于分段包装器未被激活,可以安全地捕获/重放完整 CUDA 图。对于 PIECEWISE 模式,情况类似,FULL 模式包装器与 PIECEWISE 模式包装器之间不存在冲突。对于 NONE 运行时模式,FULL 和 PIECEWISE 包装器都不会被激活,因此我们简单地回退到急切执行。
完整 CUDA 图捕获与预热¶
CUDA 图捕获发生在运行器首次调用模型前向传播(使用 _dummy_run)且运行时模式不是 NONE 时。对于完整 CUDA 图捕获,我们通过正确设置注意力元数据来显式捕获不同情况(即 prefill/mixed batch 或 uniform_decode batch),以确保底层注意力后端启动所需的内核例程。为了区分 prefill/mixed batch 或 uniform_decode batch,最重要的属性是 attn_metadata 中的 max_query_len(对大多数注意力后端都为真)。我们将其设置为 uniform_decode 的期望 uniform_query_len,否则对于非 uniform_decode batch,我们将其设置为 num_tokens。
CUDA 图包装器不再管理预热逻辑。预热过程现在由 GPU 模型运行器直接控制,其中 NONE 运行时模式被分配用于预热期间的急切执行。在为完整 CUDA 图预热时,重要的是在预热 dummy_run 调用期间显式运行注意力计算。
注意力后端的 CUDA 图兼容性¶
为了标识注意力后端的 CUDA 图兼容性,我们引入了一个新的枚举类型 AttentionCGSupport,它是一个枚举类型,用于跟踪注意力后端支持 CUDA 图的能力。该值按能力排序,即 ALWAYS> UNIFORM_BATCH> UNIFORM_SINGLE_TOKEN_DECODE> NEVER。
class AttentionCGSupport(enum.Enum):
""" 常量,用于注意力后端的 CUDA 图支持
这里我们不考虑级联注意力,因为目前
它从不支持 CUDA 图。"""
ALWAYS = 3
"""始终支持 CUDA 图;支持混合填充解码"""
UNIFORM_BATCH = 2
"""对仅包含相同查询长度批次的 CUDA 图支持,
可用于推测解码
即 "解码" 为 1 + num_speculative_tokens"""
UNIFORM_SINGLE_TOKEN_DECODE = 1
"""对仅包含查询长度为 1 的解码批次的 CUDA 图支持"""
NEVER = 0
"""不支持 CUDA 图"""
假设我们有混合注意力后端(例如,在 mamba mixer 模型中)。在这种情况下,我们寻求所有后端的最小能力来确定模型的最终能力,并可能通过降级模式来解决不兼容的 CUDA 图模式。例如,在 -O3 编译模式下,如果最小能力是 UNIFORM_BATCH,则将 FULL 模式降级为 FULL_AND_PIECEWISE 模式,或者如果最小能力是 NEVER,则降级为 PIECEWISE 模式。有关完整的回退策略,请参见 此代码。
下表列出了在撰写本文时支持完整 CUDA 图的后端。
| 注意力后端 | cudagraph_support | 说明 |
|---|---|---|
| FlashAttention v2 | UNIFORM_BATCH | 实际上是 ALWAYS,但为了性能原因采用变通方案回退到 FULL_AND_PIECEWISE |
| FlashAttention v3 | ALWAYS | 对两种批次都有统一的处理流程,因此 FULL 模式表现良好 |
| Triton Attention | ALWAYS | 由于对预填充/混合批次和纯解码批次有不同的内核,因此更偏好 FULL_AND_PIECEWISE |
| AITER FlashAttention | UNIFORM_BATCH | |
| FlashInfer | UNIFORM_SINGLE_TOKEN_DECODE | 在 Blackwell 上使用 TRTLLM 注意力时将设置为 UNIFORM_BATCH |
| FlashMLA | UNIFORM_BATCH | |
| FlashInferMLA | UNIFORM_BATCH | |
| AITER MLA | UNIFORM_SINGLE_TOKEN_DECODE | |
| CUTLASS MLA | UNIFORM_SINGLE_TOKEN_DECODE | |
| Mamba attention | UNIFORM_SINGLE_TOKEN_DECODE |
未列出的后端均声明为 NEVER。
使用指南¶
现在 CLI 直接使用 cudagraph_mode 的大写字符串作为 compilation_config:--compilation-config '{"cudagraph_mode": "..."}',其中 ... 应为以下之一:NONE、PIECEWISE、FULL、FULL_DECODE_ONLY 或 FULL_AND_PIECEWISE。请注意,所有与 PIECEWISE 相关的模式都需要分段编译,所有与 FULL 相关的模式都需要注意力后端的 CUDA Graph 支持。例如:
vllm serve --model meta-llama/Llama-3.1-8B-Instruct --compilation-config '{"cudagraph_mode": "FULL_AND_PIECEWISE"}'
Python 示例¶
import os
os.environ.setdefault("VLLM_LOGGING_LEVEL", "DEBUG")
import vllm
from vllm.config import CUDAGraphMode
compilation_config = {"mode": 3, "cudagraph_mode": "FULL_AND_PIECEWISE"}
model = vllm.LLM(
model="meta-llama/Llama-3.1-8B-Instruct",
dtype="auto",
compilation_config=compilation_config,
)
sampling_params = vllm.SamplingParams(
temperature=0, # 贪婪解码
max_tokens=1024,
)
outputs = model.generate(
["My name is John and"],
sampling_params=sampling_params,
)
分段编译与完整图自定义传递(注意力融合、序列并行)¶
不幸的是,某些自定义编译传递必须看到整个图才能生效,因此与分段编译不兼容。这包括 AttnFusionPass 和 SequenceParallelismPass。作为短期解决方案,当启用注意力融合时,我们自动禁用分段编译(通过设置 splitting_ops=[])。我们使用 CUDA 图模式 FULL 或 FULL_DECODE_ONLY(取决于后端支持)。然而,这导致了另一个优化不兼容性和令人困惑的性能权衡。
长期来看,我们在 Inductor 中增加了图分区的能力,而不是在 Dynamo 之后立即进行。可以通过 CompilationConfig.use_inductor_graph_partition=True 启用,但目前是实验性的,仅在 torch>=2.9 时可用。这也会增加编译时间,因为它必须编译整个图,无法重用分段编译工件。一旦 vLLM 支持 2.9,我们计划使其成为默认方法,因为这也将加快分段 cudagraph 捕获速度。
关于性能¶
请参阅以下链接以获取示例: