Hugging Face 推理端点¶
概述¶
与 vLLM 兼容的模型可以部署在 Hugging Face 推理端点上,既可以从 Hugging Face Hub 开始,也可以直接从 推理端点 界面开始。这允许您在完全托管的环境中提供模型服务,具有 GPU 加速、自动扩展和监控功能,而无需手动管理基础设施。
有关 vLLM 集成和部署选项的高级详细信息,请参阅高级部署详细信息。
部署方法¶
- 方法 1:从目录部署。 从 Hugging Face Hub 一键部署模型,使用现成的优化配置。
- 方法 2:引导式部署(Transformers 模型)。 使用 Deploy 按钮从 Hub UI 即时部署带有
transformers标签的模型。 - 方法 3:手动部署(高级模型)。 适用于使用带有
transformers标签的自定义代码的模型,或不使用标准transformers但受 vLLM 支持的模型。此方法需要手动配置。
方法 1:从目录部署¶
这是在 Hugging Face 推理端点上开始使用 vLLM 的最简单方法。您可以在 推理端点 浏览经过验证和优化的模型部署配置目录,以最大化性能。
-
转到 端点目录,在 推理服务器 选项中选择
vLLM。这将显示当前具有优化预配置选项的模型列表。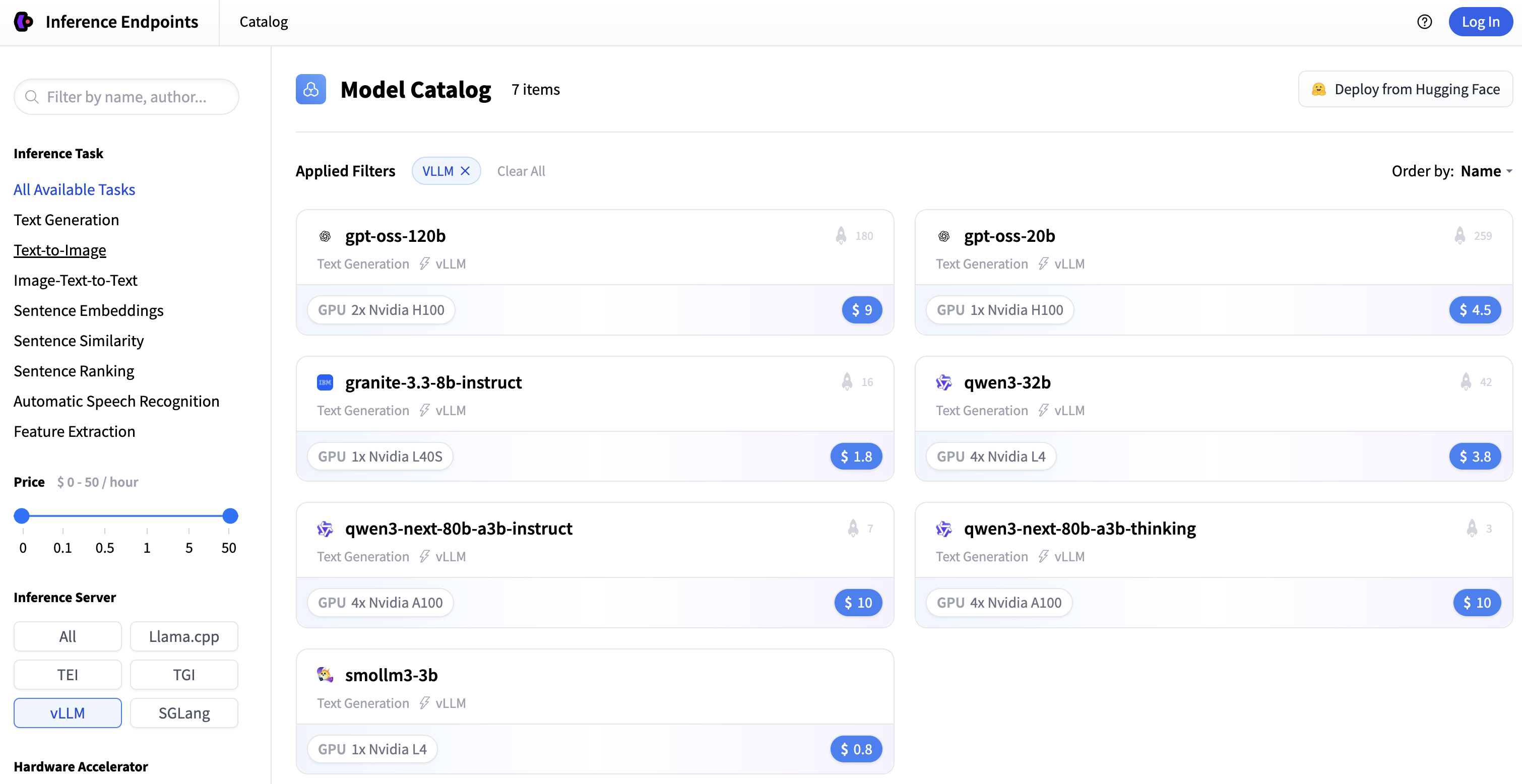
-
选择所需的模型,然后点击 创建端点。
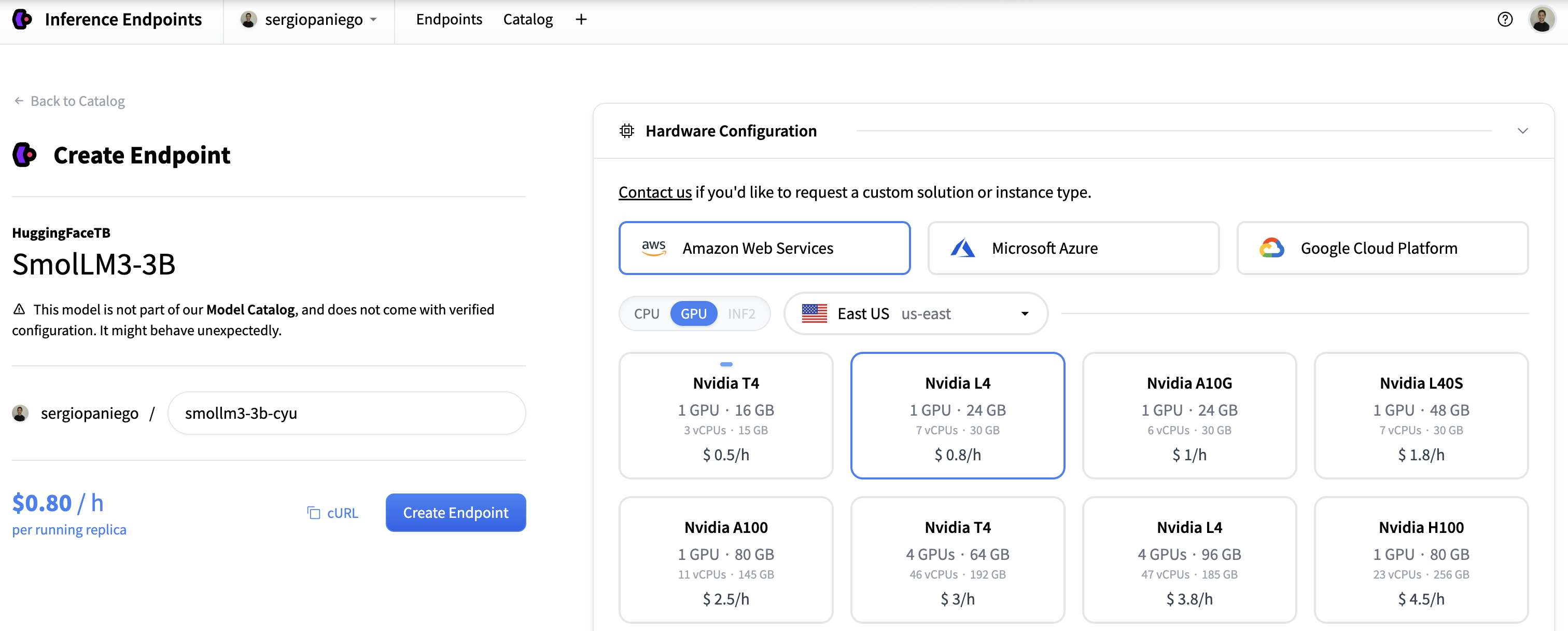
-
部署完成后,您可以使用端点。使用控制台中提供的 URL 更新
DEPLOYMENT_URL,记得根据需要附加/v1。# pip install openai from openai import OpenAI import os client = OpenAI( base_url=DEPLOYMENT_URL, api_key=os.environ["HF_TOKEN"], # https://huggingface.co/settings/tokens ) chat_completion = client.chat.completions.create( model="HuggingFaceTB/SmolLM3-3B", messages=[ { "role": "user", "content": [ { "type": "text", "text": "用简单的术语简要解释一下重力。", } ], } ], stream=True, ) for message in chat_completion: print(message.choices[0].delta.content, end="")
Note
目录提供了针对 vLLM 优化的模型,包括 GPU 设置和推理引擎配置。您可以从推理端点 UI 监控端点并更新 容器或其配置。
方法 2:引导式部署(Transformers 模型)¶
此方法适用于元数据中具有 transformers 库标签 的模型。它允许您直接从 Hub UI 部署模型,而无需手动配置。
-
导航到 Hugging Face Hub 上的模型。
在此示例中,我们将使用ibm-granite/granite-docling-258M模型。您可以通过检查 README 中的前言来验证模型是否兼容,其中库被标记为library: transformers。 -
找到 Deploy 按钮。该按钮出现在带有
transformers标签的模型的 模型卡 右上角。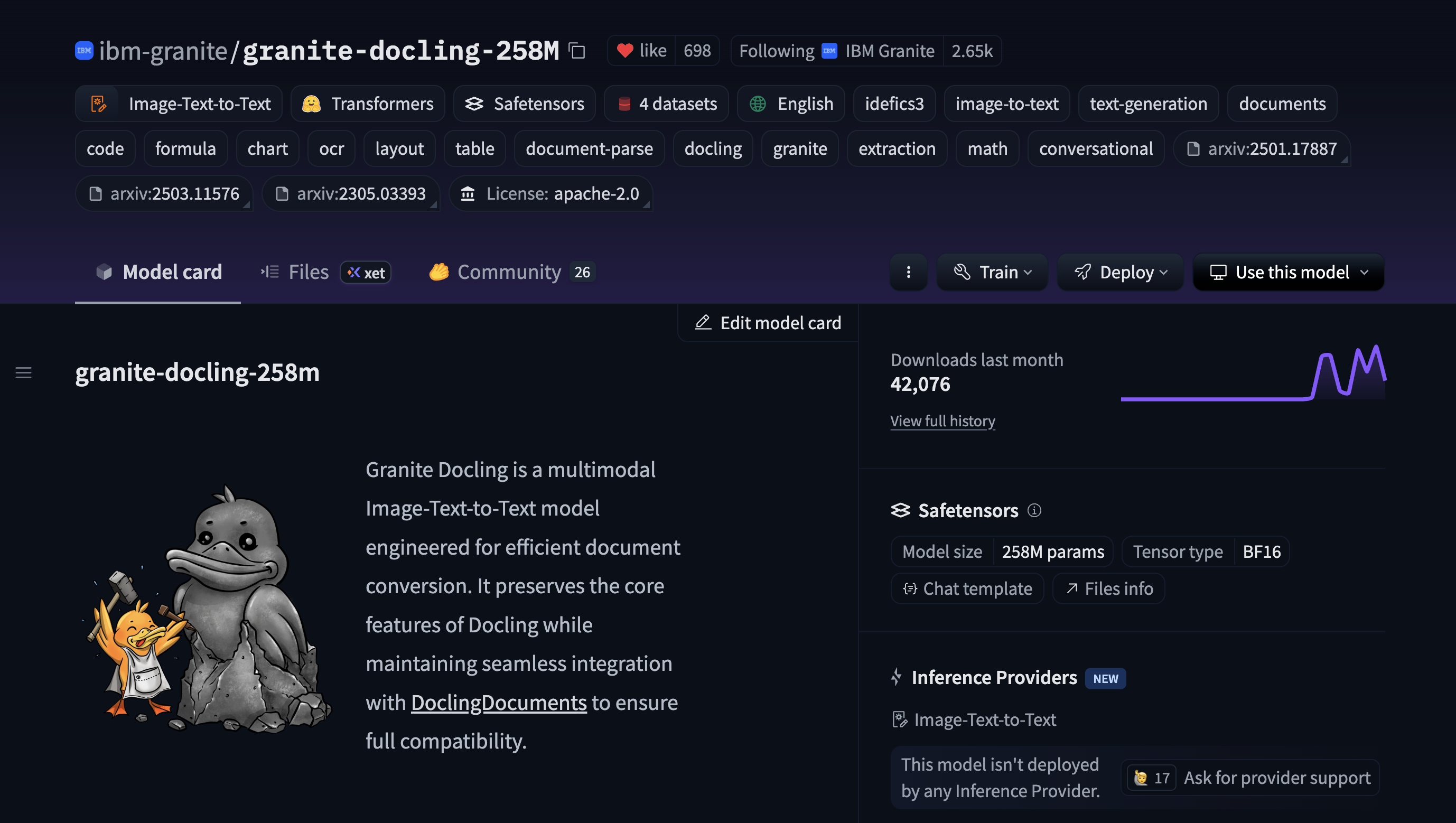
-
点击 Deploy 按钮 > HF 推理端点。您将被带到推理端点界面来配置部署。
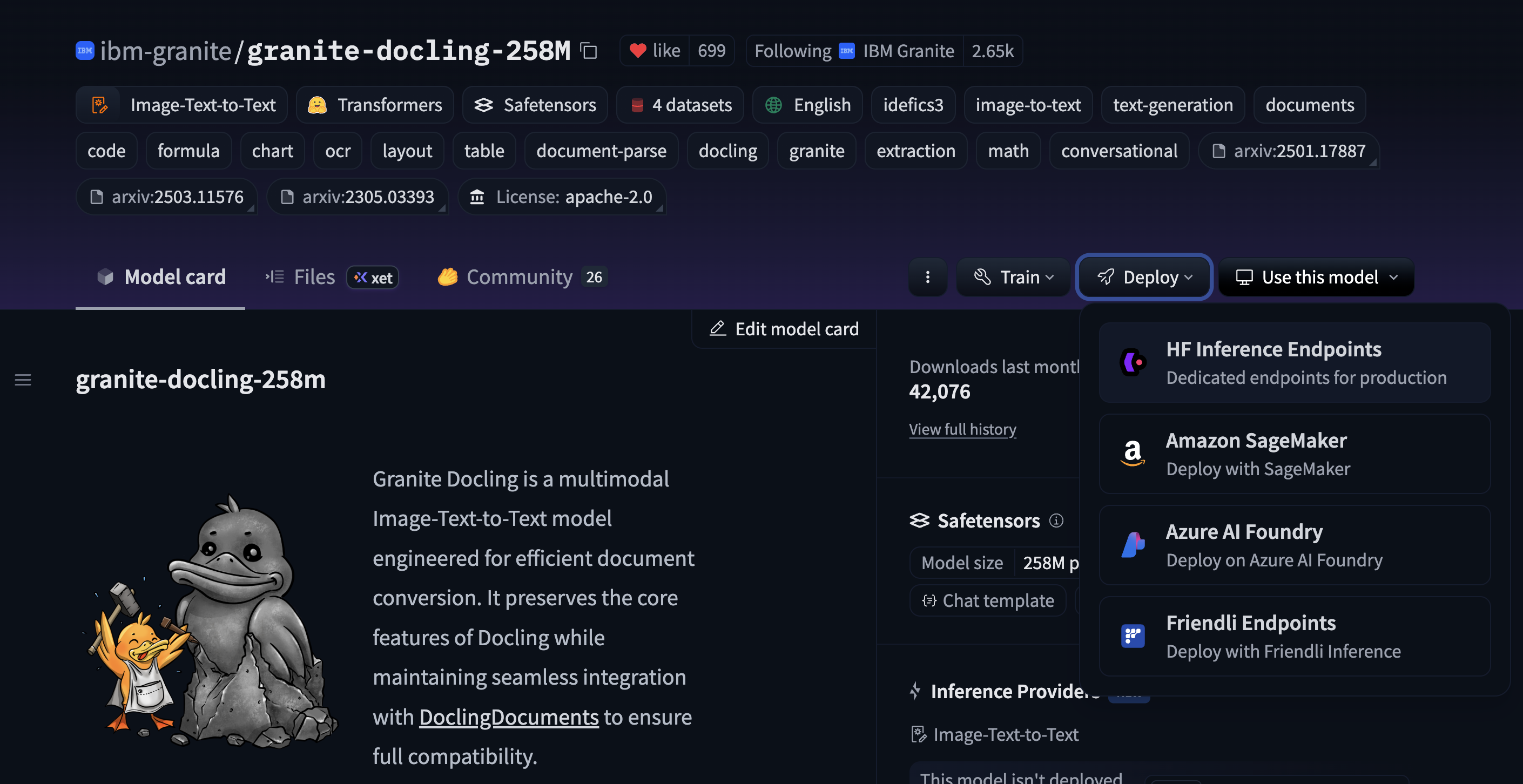
-
选择硬件(我们为此示例选择 AWS>GPU>T4)和容器配置。选择
vLLM作为容器类型,然后按 创建端点 完成部署。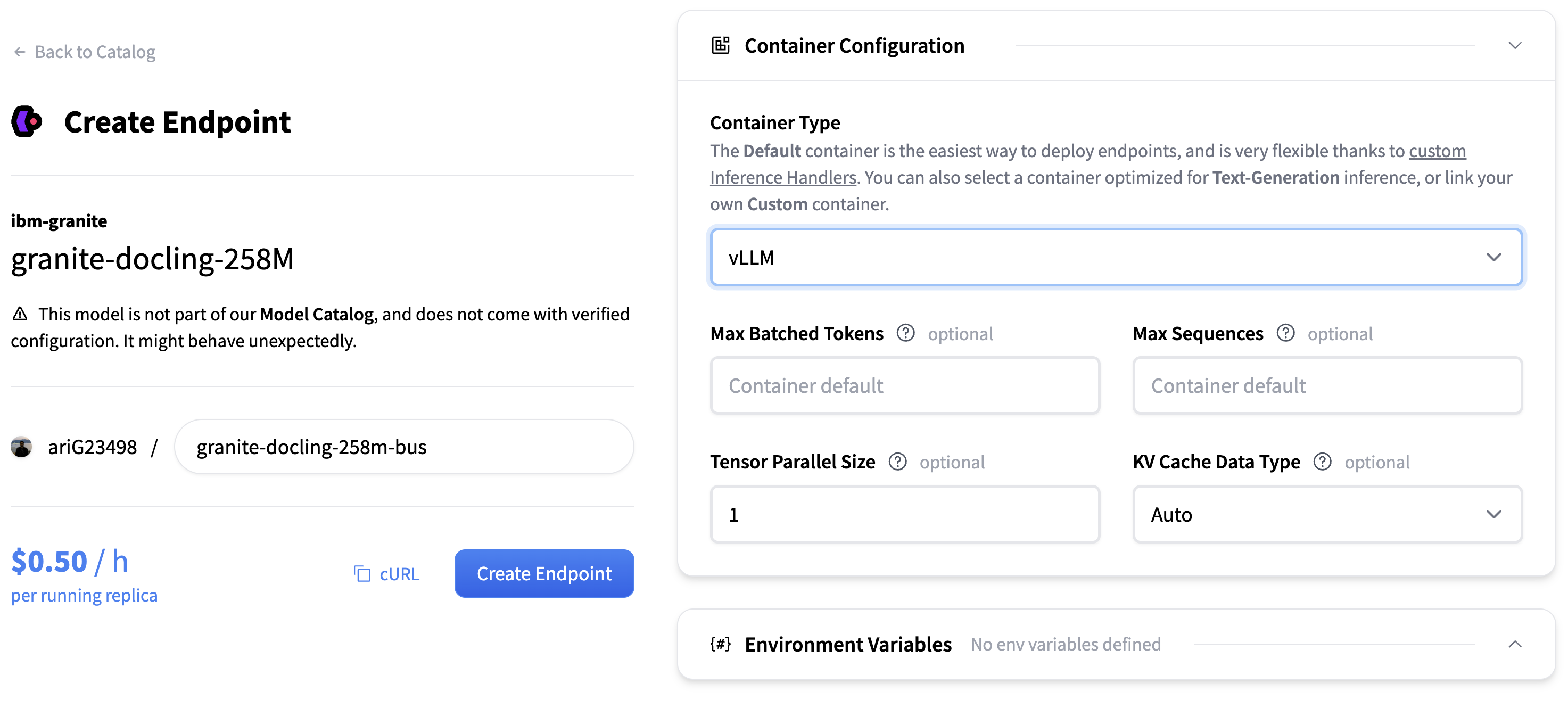
-
使用已部署的端点。使用控制台中提供的 URL 更新
DEPLOYMENT_URL(记得添加所需的/v1)。然后,您可以通过编程方式或使用 SDK 使用您的端点。# pip install openai from openai import OpenAI import os client = OpenAI( base_url=DEPLOYMENT_URL, api_key=os.environ["HF_TOKEN"], # https://huggingface.co/settings/tokens ) chat_completion = client.chat.completions.create( model="ibm-granite/granite-docling-258M", messages=[ { "role": "user", "content": [ { "type": "image_url", "image_url": { "url": "https://huggingface.co/ibm-granite/granite-docling-258M/resolve/main/assets/new_arxiv.png", }, }, { "type": "text", "text": "将此页面转换为 docling。", }, ] } ], stream=True, ) for message in chat_completion: print(message.choices[0].delta.content, end="")
Note
此方法使用最佳猜测的默认值。您可能需要调整配置以满足您的特定要求。
方法 3:手动部署(高级模型)¶
某些模型需要手动部署,因为它们:
- 使用带有
transformers标签的自定义代码 - 不使用标准
transformers但受vLLM支持
这些模型无法使用模型卡上的 Deploy 按钮进行部署。
在本指南中,我们使用 rednote-hilab/dots.ocr 模型演示手动部署,这是一个与 vLLM 集成的 OCR 模型(参见 vLLM PR)。
-
开始新的部署。转到 推理端点 并点击
新建。
-
在 Hub 中搜索模型。在对话框中,切换到 Hub 并搜索所需的模型。
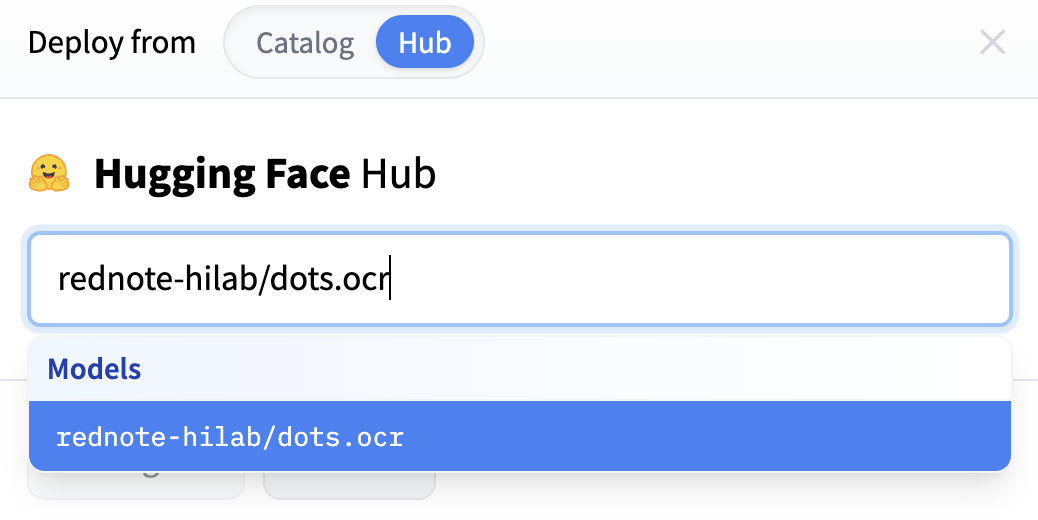
-
选择基础设施。在配置页面上,从可用选项中选择云提供商和硬件。
为此演示,我们选择 AWS 和 L4 GPU。根据您的硬件需求进行调整。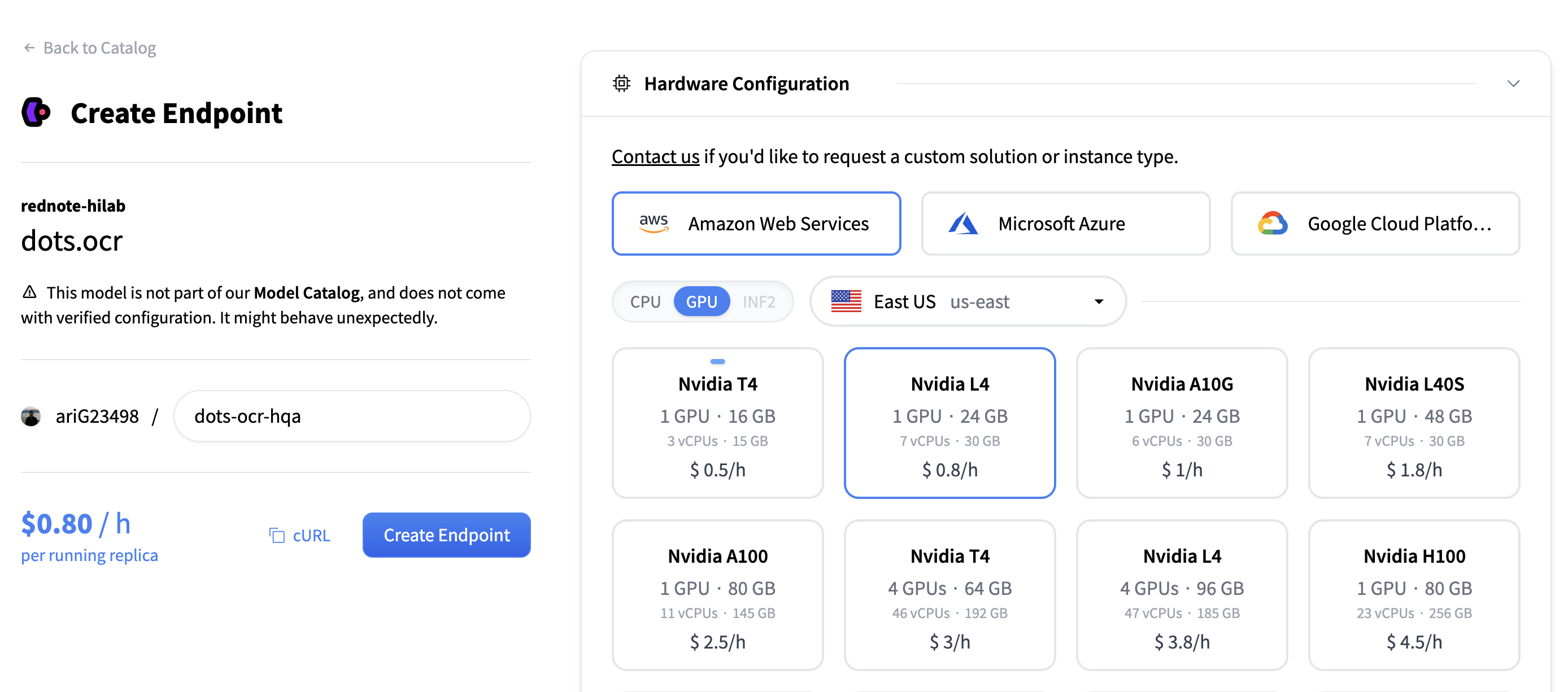
-
配置容器。滚动到 容器配置 并选择
vLLM作为容器类型。
-
创建端点。点击 创建端点 以部署模型。
端点准备就绪后,您可以使用 OpenAI 补全 API、cURL 或其他 SDK 使用它。如果需要,请记得在部署 URL 后附加
/v1。
Note
您可以从推理端点 UI 调整容器设置(容器 URI、容器参数),然后点击更新端点。这将使用更新后的容器配置重新部署端点。对模型本身的更改需要创建新的端点或使用不同的模型重新部署。例如,在此演示中,您可能需要将容器 URI 更新为 nightly 镜像 (vllm/vllm-openai:nightly),并在容器参数中添加 --trust-remote-code 标志。
高级部署详情¶
通过 Transformers 建模后端集成,vLLM 现在为任何与 transformers 兼容的模型提供 Day 0 支持。这意味着您可以立即部署此类模型,利用 vLLM 优化的推理能力,而无需额外的后端修改。
Hugging Face 推理端点提供了一个完全托管的环境,用于通过 vLLM 提供模型服务。您可以部署模型而无需配置服务器、安装依赖项或管理集群。端点还支持跨多个云提供商(AWS、Azure、GCP)部署,而无需单独的账户。
该平台与 Hugging Face Hub 无缝集成,允许您部署任何与 vLLM 或 transformers 兼容的模型,跟踪使用情况,并直接更新推理引擎。vLLM 引擎已预配置,可实现优化的推理,并轻松在模型或引擎之间切换,而无需修改代码。这种设置简化了生产部署:端点在几分钟内即可准备就绪,包含监控和日志记录,让您专注于提供模型服务,而不是维护基础设施。
后续步骤¶
- 探索 推理端点 模型目录
- 阅读推理端点文档
- 了解推理端点引擎
- 了解 Transformers 建模后端集成