基准测试 CLI¶
本节将指导您使用 vLLM 支持的海量数据集运行基准测试。
本文档会持续更新,以反映新功能和数据集的发布。
数据集概览¶
| 数据集 | 在线 | 离线 | 数据路径 |
|---|---|---|---|
| ShareGPT | ✅ | ✅ | wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json |
| ShareGPT4V(图像) | ✅ | ✅ | wget https://huggingface.co/datasets/Lin-Chen/ShareGPT4V/resolve/main/sharegpt4v_instruct_gpt4-vision_cap100k.json注意:图像需要单独下载。例如,要下载 COCO 2017 训练集图像: wget http://images.cocodataset.org/zips/train2017.zip |
| ShareGPT4Video(视频) | ✅ | ✅ | git clone https://huggingface.co/datasets/ShareGPT4Video/ShareGPT4Video |
| BurstGPT | ✅ | ✅ | wget https://github.com/HPMLL/BurstGPT/releases/download/v1.1/BurstGPT_without_fails_2.csv |
| Sonnet(已弃用) | ✅ | ✅ | 本地文件:benchmarks/sonnet.txt |
| Random | ✅ | ✅ | synthetic |
| RandomMultiModal(图像/视频) | 🟡 | 🚧 | synthetic |
| RandomForReranking | ✅ | ✅ | synthetic |
| Prefix Repetition | ✅ | ✅ | synthetic |
| HuggingFace-VisionArena | ✅ | ✅ | lmarena-ai/VisionArena-Chat |
| HuggingFace-MMVU | ✅ | ✅ | yale-nlp/MMVU |
| HuggingFace-InstructCoder | ✅ | ✅ | likaixin/InstructCoder |
| HuggingFace-AIMO | ✅ | ✅ | AI-MO/aimo-validation-aime、AI-MO/NuminaMath-1.5、AI-MO/NuminaMath-CoT |
| HuggingFace-Other | ✅ | ✅ | lmms-lab/LLaVA-OneVision-Data、Aeala/ShareGPT_Vicuna_unfiltered |
| HuggingFace-MTBench | ✅ | ✅ | philschmid/mt-bench |
| HuggingFace-Blazedit | ✅ | ✅ | vdaita/edit_5k_char、vdaita/edit_10k_char |
| Spec Bench | ✅ | ✅ | wget https://raw.githubusercontent.com/hemingkx/Spec-Bench/refs/heads/main/data/spec_bench/question.jsonl |
| Custom | ✅ | ✅ | 本地文件:data.jsonl |
图例:
- ✅ - 已支持
- 🟡 - 部分支持
- 🚧 - 即将支持
Note
HuggingFace 数据集的 dataset-name 应设置为 hf。 对于本地 dataset-path,请将 hf-name 设置为对应的 Hugging Face ID,例如:
示例¶
🚀 在线基准测试¶
展开查看
首先启动模型服务:
然后运行基准测试脚本:
# 下载数据集
# wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
vllm bench serve \
--backend vllm \
--model NousResearch/Hermes-3-Llama-3.1-8B \
--endpoint /v1/completions \
--dataset-name sharegpt \
--dataset-path <your data path>/ShareGPT_V3_unfiltered_cleaned_split.json \
--num-prompts 10
如果成功,您将看到如下输出:
============ Serving Benchmark Result ============
Successful requests: 10
Benchmark duration (s): 5.78
Total input tokens: 1369
Total generated tokens: 2212
Request throughput (req/s): 1.73
Output token throughput (tok/s): 382.89
Total token throughput (tok/s): 619.85
---------------Time to First Token----------------
Mean TTFT (ms): 71.54
Median TTFT (ms): 73.88
P99 TTFT (ms): 79.49
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 7.91
Median TPOT (ms): 7.96
P99 TPOT (ms): 8.03
---------------Inter-token Latency----------------
Mean ITL (ms): 7.74
Median ITL (ms): 7.70
P99 ITL (ms): 8.39
==================================================
自定义数据集¶
如果您要测试的数据集尚未被 vLLM 支持,您仍然可以使用 CustomDataset 对其进行基准测试。您的数据需要是 .jsonl 格式,并且每条记录需包含 "prompt" 字段,例如 data.jsonl:
{"prompt": "What is the capital of India?"}
{"prompt": "What is the capital of Iran?"}
{"prompt": "What is the capital of China?"}
# 运行基准测试脚本
vllm bench serve --port 9001 --save-result --save-detailed \
--backend vllm \
--model meta-llama/Llama-3.1-8B-Instruct \
--endpoint /v1/completions \
--dataset-name custom \
--dataset-path <path-to-your-data-jsonl> \
--custom-skip-chat-template \
--num-prompts 80 \
--max-concurrency 1 \
--temperature=0.3 \
--top-p=0.75 \
--result-dir "./log/"
如果您的数据已经应用了聊天模板,可以使用 --custom-skip-chat-template 跳过模板应用。
视觉语言模型的 VisionArena 基准测试¶
vllm bench serve \
--backend openai-chat \
--model Qwen/Qwen2-VL-7B-Instruct \
--endpoint /v1/chat/completions \
--dataset-name hf \
--dataset-path lmarena-ai/VisionArena-Chat \
--hf-split train \
--num-prompts 1000
使用推测解码的 InstructCoder 基准测试¶
vllm serve meta-llama/Meta-Llama-3-8B-Instruct \
--speculative-config $'{"method": "ngram",
"num_speculative_tokens": 5, "prompt_lookup_max": 5,
"prompt_lookup_min": 2}'
vllm bench serve \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--dataset-name hf \
--dataset-path likaixin/InstructCoder \
--num-prompts 2048
使用推测解码的 Spec Bench 基准测试¶
vllm serve meta-llama/Meta-Llama-3-8B-Instruct \
--speculative-config $'{"method": "ngram",
"num_speculative_tokens": 5, "prompt_lookup_max": 5,
"prompt_lookup_min": 2}'
运行所有类别:
# 使用以下命令下载数据集:
# wget https://raw.githubusercontent.com/hemingkx/Spec-Bench/refs/heads/main/data/spec_bench/question.jsonl
vllm bench serve \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--dataset-name spec_bench \
--dataset-path "<YOUR_DOWNLOADED_PATH>/data/spec_bench/question.jsonl" \
--num-prompts -1
可用类别包括 [writing, roleplay, reasoning, math, coding, extraction, stem, humanities, translation, summarization, qa, math_reasoning, rag]。
仅运行特定类别,例如 "summarization":
vllm bench serve \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--dataset-name spec_bench \
--dataset-path "<YOUR_DOWNLOADED_PATH>/data/spec_bench/question.jsonl" \
--num-prompts -1
--spec-bench-category "summarization"
其他 HuggingFace 数据集示例¶
lmms-lab/LLaVA-OneVision-Data:
vllm bench serve \
--backend openai-chat \
--model Qwen/Qwen2-VL-7B-Instruct \
--endpoint /v1/chat/completions \
--dataset-name hf \
--dataset-path lmms-lab/LLaVA-OneVision-Data \
--hf-split train \
--hf-subset "chart2text(cauldron)" \
--num-prompts 10
Aeala/ShareGPT_Vicuna_unfiltered:
vllm bench serve \
--backend openai-chat \
--model Qwen/Qwen2-VL-7B-Instruct \
--endpoint /v1/chat/completions \
--dataset-name hf \
--dataset-path Aeala/ShareGPT_Vicuna_unfiltered \
--hf-split train \
--num-prompts 10
AI-MO/aimo-validation-aime:
vllm bench serve \
--model Qwen/QwQ-32B \
--dataset-name hf \
--dataset-path AI-MO/aimo-validation-aime \
--num-prompts 10 \
--seed 42
philschmid/mt-bench:
vllm bench serve \
--model Qwen/QwQ-32B \
--dataset-name hf \
--dataset-path philschmid/mt-bench \
--num-prompts 80
vdaita/edit_5k_char 或 vdaita/edit_10k_char:
vllm bench serve \
--model Qwen/QwQ-32B \
--dataset-name hf \
--dataset-path vdaita/edit_5k_char \
--num-prompts 90 \
--blazedit-min-distance 0.01 \
--blazedit-max-distance 0.99
使用采样参数运行¶
当使用兼容 OpenAI 的后端(如 vllm)时,可以指定可选的采样参数。客户端命令示例:
vllm bench serve \
--backend vllm \
--model NousResearch/Hermes-3-Llama-3.1-8B \
--endpoint /v1/completions \
--dataset-name sharegpt \
--dataset-path <your data path>/ShareGPT_V3_unfiltered_cleaned_split.json \
--top-k 10 \
--top-p 0.9 \
--temperature 0.5 \
--num-prompts 10
使用递增请求速率运行¶
基准测试工具还支持在基准测试运行期间逐步提高请求速率。这对于对服务器进行压力测试或找到其在给定延迟预算下可以处理的最大吞吐量非常有用。
支持两种递增策略:
linear:将请求速率从起始值线性增加到结束值。exponential:将请求速率指数级增加。
可以使用以下参数来控制递增:
--ramp-up-strategy:要使用的递增策略(linear或exponential)。--ramp-up-start-rps:基准测试开始时的请求速率。--ramp-up-end-rps:基准测试结束时的请求速率。
负载模式配置¶
vLLM 的基准测试服务脚本通过三个关键参数提供了复杂的负载模式模拟功能,这些参数控制请求生成和并发行为:
负载模式控制参数¶
--request-rate:控制目标请求生成速率(每秒请求数)。设置为inf进行最大吞吐量测试,或设置为有限值进行受控负载模拟。--burstiness:使用 Gamma 分布控制流量变异性(范围:> 0)。较低的值会产生突发性流量,较高的值会产生均匀流量。--max-concurrency:限制并发未完成的请求数。如果未提供此参数,则并发数不受限制。设置一个值以模拟背压。
这些参数协同工作,以精心选择的默认值创建真实的负载模式。--request-rate 参数默认为 inf(无限),这会立即发送所有请求以进行最大吞吐量测试。当设置为有限值时,它使用泊松过程(默认 --burstiness=1.0)或 Gamma 分布来实现真实的请求时序。--burstiness 参数仅在 --request-rate 不为无限时生效 - 值为 1.0 会产生自然的泊松流量,而较低的值(0.1-0.5)会产生突发性模式,较高的值(2.0-5.0)会产生均匀间隔。--max-concurrency 参数默认为 None(无限制),但可以设置以模拟负载均衡器或 API 网关限制并发连接的真实世界约束。当组合使用时,这些参数允许您模拟从不受限制的压力测试(--request-rate=inf)到具有真实到达模式和资源约束的生产类似场景的所有内容。
--burstiness 参数在数学上使用 Gamma 分布控制请求到达模式,其中:
- 形状参数:
burstiness值 - 变异系数 (CV):\(\frac{1}{\sqrt{burstiness}}\)
- 流量特征:
burstiness = 0.1:高度突发性流量(CV ≈ 3.16)- 压力测试burstiness = 1.0:自然泊松流量(CV = 1.0)- 真实模拟burstiness = 5.0:均匀流量(CV ≈ 0.45)- 受控负载测试
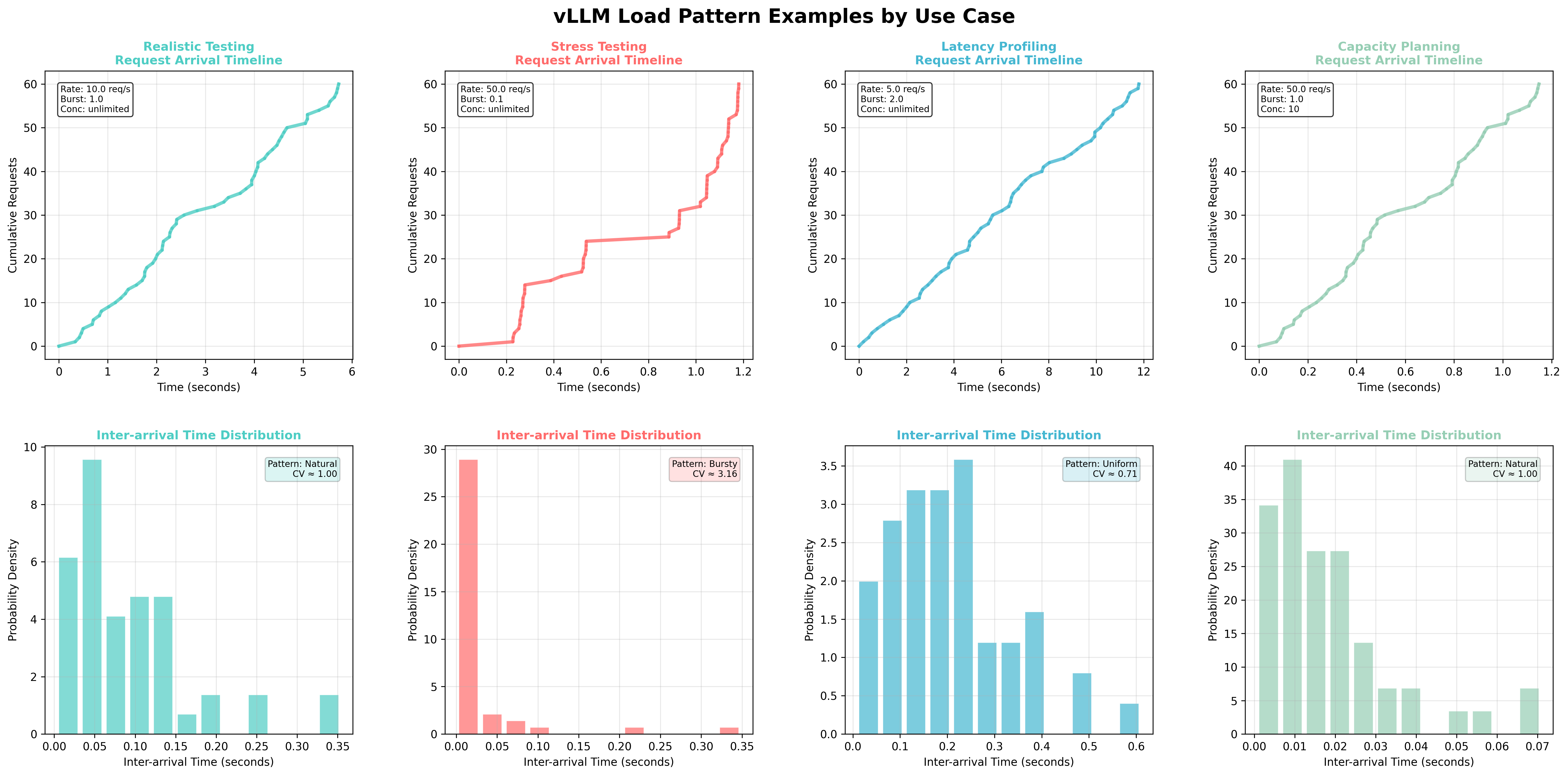
图:每种用例的负载模式示例。顶行:显示随时间累积请求的请求到达时间线。底行:显示流量变异性模式的到达间隔时间分布。每列代表具有其特定参数设置和结果流量特征的不同用例。
按用例的负载模式建议:
| 用例 | 突发性 | 请求速率 | 最大并发数 | 描述 |
|---|---|---|---|---|
| 最大吞吐量 | 不适用 | 无限 | 有限 | 最常见:在无限用户需求下模拟负载均衡器/网关限制 |
| 真实测试 | 1.0 | 中等 (5-20) | 无限 | 用于基线性能的自然泊松流量模式 |
| 压力测试 | 0.1-0.5 | 高 (20-100) | 无限 | 具有挑战性的突发模式以测试弹性 |
| 延迟分析 | 2.0-5.0 | 低 (1-10) | 无限 | 用于一致时序分析的均匀负载 |
| 容量规划 | 1.0 | 可变 | 有限 | 在真实约束下测试资源限制 |
| SLA 验证 | 1.0 | 目标速率 | SLA 限制 | 用于合规性测试的生产类似约束 |
这些负载模式有助于评估 vLLM 部署的不同方面,从基本性能特征到在挑战性流量条件下的弹性。
最大吞吐量 模式(--request-rate=inf --max-concurrency=<limit>)是生产基准测试中最常用的配置。这模拟了真实世界的部署架构,其中:
- 用户可以尽可能快地发送请求(无限速率)
- 负载均衡器或 API 网关控制最大并发连接数
- 系统在其并发限制下运行,揭示真实的吞吐量能力
- 当速率为无限时,
--burstiness不起作用,因为不控制请求时序
此模式有助于确定生产负载均衡器配置的最佳并发设置。
要有效地配置负载模式,特别是对于 容量规划 和 SLA 验证 用例,您需要了解系统的资源限制。在启动期间,vLLM 报告 KV 缓存配置,这直接影响您的负载测试参数:
其中:
- GPU KV 缓存大小:所有并发请求可以缓存的总 token 数
- 最大并发数:给定
max_model_len的理论最大并发请求数 - 计算:
max_concurrency = kv_cache_size / max_model_len
使用 KV 缓存指标进行负载模式配置:
- 对于容量规划:将
--max-concurrency设置为报告最大值的 80-90%,以测试真实的资源约束 - 对于 SLA 验证:使用报告的最大值作为您的 SLA 限制,以确保合规性测试与生产能力匹配
- 对于真实测试:在接近理论限制时监控内存使用情况,以了解可持续的请求速率
- 请求速率指导:使用 KV 缓存大小来估计特定工作负载和序列长度的可持续请求速率
📈 离线吞吐量基准测试¶
显示更多
vllm bench throughput \
--model NousResearch/Hermes-3-Llama-3.1-8B \
--dataset-name sonnet \
--dataset-path vllm/benchmarks/sonnet.txt \
--num-prompts 10
如果成功,您将看到以下输出
视觉语言模型的 VisionArena 基准测试¶
vllm bench throughput \
--model Qwen/Qwen2-VL-7B-Instruct \
--backend vllm-chat \
--dataset-name hf \
--dataset-path lmarena-ai/VisionArena-Chat \
--num-prompts 1000 \
--hf-split train
现在,num prompt tokens 包括图像 token 计数
使用推测解码的 InstructCoder 基准测试¶
VLLM_WORKER_MULTIPROC_METHOD=spawn \
vllm bench throughput \
--dataset-name=hf \
--dataset-path=likaixin/InstructCoder \
--model=meta-llama/Meta-Llama-3-8B-Instruct \
--input-len=1000 \
--output-len=100 \
--num-prompts=2048 \
--async-engine \
--speculative-config $'{"method": "ngram",
"num_speculative_tokens": 5, "prompt_lookup_max": 5,
"prompt_lookup_min": 2}'
其他 HuggingFace 数据集示例¶
lmms-lab/LLaVA-OneVision-Data:
vllm bench throughput \
--model Qwen/Qwen2-VL-7B-Instruct \
--backend vllm-chat \
--dataset-name hf \
--dataset-path lmms-lab/LLaVA-OneVision-Data \
--hf-split train \
--hf-subset "chart2text(cauldron)" \
--num-prompts 10
Aeala/ShareGPT_Vicuna_unfiltered:
vllm bench throughput \
--model Qwen/Qwen2-VL-7B-Instruct \
--backend vllm-chat \
--dataset-name hf \
--dataset-path Aeala/ShareGPT_Vicuna_unfiltered \
--hf-split train \
--num-prompts 10
AI-MO/aimo-validation-aime:
vllm bench throughput \
--model Qwen/QwQ-32B \
--backend vllm \
--dataset-name hf \
--dataset-path AI-MO/aimo-validation-aime \
--hf-split train \
--num-prompts 10
使用 LoRA 适配器的基准测试:
# 下载数据集
# wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
vllm bench throughput \
--model meta-llama/Llama-2-7b-hf \
--backend vllm \
--dataset_path <your data path>/ShareGPT_V3_unfiltered_cleaned_split.json \
--dataset_name sharegpt \
--num-prompts 10 \
--max-loras 2 \
--max-lora-rank 8 \
--enable-lora \
--lora-path yard1/llama-2-7b-sql-lora-test
🛠️ 结构化输出基准测试¶
展开查看
对结构化输出生成(JSON、语法、正则表达式)的性能进行基准测试。
服务器设置¶
JSON 模式基准测试¶
python3 benchmarks/benchmark_serving_structured_output.py \
--backend vllm \
--model NousResearch/Hermes-3-Llama-3.1-8B \
--dataset json \
--structured-output-ratio 1.0 \
--request-rate 10 \
--num-prompts 1000
基于语法的生成基准测试¶
python3 benchmarks/benchmark_serving_structured_output.py \
--backend vllm \
--model NousResearch/Hermes-3-Llama-3.1-8B \
--dataset grammar \
--structure-type grammar \
--request-rate 10 \
--num-prompts 1000
基于正则表达式的生成基准测试¶
python3 benchmarks/benchmark_serving_structured_output.py \
--backend vllm \
--model NousResearch/Hermes-3-Llama-3.1-8B \
--dataset regex \
--request-rate 10 \
--num-prompts 1000
基于选择的生成基准测试¶
python3 benchmarks/benchmark_serving_structured_output.py \
--backend vllm \
--model NousResearch/Hermes-3-Llama-3.1-8B \
--dataset choice \
--request-rate 10 \
--num-prompts 1000
XGrammar 基准测试数据集¶
📚 长文档问答基准测试¶
展开查看
对启用前缀缓存的长文档问答性能进行基准测试。
基础长文档问答测试¶
python3 benchmarks/benchmark_long_document_qa_throughput.py \
--model meta-llama/Llama-2-7b-chat-hf \
--enable-prefix-caching \
--num-documents 16 \
--document-length 2000 \
--output-len 50 \
--repeat-count 5
不同重复模式¶
# 随机模式(默认)- 随机打乱提示
python3 benchmarks/benchmark_long_document_qa_throughput.py \
--model meta-llama/Llama-2-7b-chat-hf \
--enable-prefix-caching \
--num-documents 8 \
--document-length 3000 \
--repeat-count 3 \
--repeat-mode random
# 平铺模式 - 按顺序重复整个提示列表
python3 benchmarks/benchmark_long_document_qa_throughput.py \
--model meta-llama/Llama-2-7b-chat-hf \
--enable-prefix-caching \
--num-documents 8 \
--document-length 3000 \
--repeat-count 3 \
--repeat-mode tile
# 交错模式 - 连续重复每个提示
python3 benchmarks/benchmark_long_document_qa_throughput.py \
--model meta-llama/Llama-2-7b-chat-hf \
--enable-prefix-caching \
--num-documents 8 \
--document-length 3000 \
--repeat-count 3 \
--repeat-mode interleave
🗂️ 前缀缓存基准测试¶
展开查看
对自动前缀缓存的效率进行基准测试。
启用前缀缓存的固定提示¶
python3 benchmarks/benchmark_prefix_caching.py \
--model meta-llama/Llama-2-7b-chat-hf \
--enable-prefix-caching \
--num-prompts 1 \
--repeat-count 100 \
--input-length-range 128:256
使用 ShareGPT 数据集和前缀缓存¶
# 下载数据集
# wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
python3 benchmarks/benchmark_prefix_caching.py \
--model meta-llama/Llama-2-7b-chat-hf \
--dataset-path /path/ShareGPT_V3_unfiltered_cleaned_split.json \
--enable-prefix-caching \
--num-prompts 20 \
--repeat-count 5 \
--input-length-range 128:256
前缀重复数据集¶
🧪 哈希基准测试¶
展开查看
benchmarks/ 目录中有两个辅助脚本,用于比较前缀缓存及相关工具所使用的哈希选项。这两个脚本均为独立运行(无需服务器),可在生产环境中启用前缀缓存前帮助选择合适的哈希算法。
benchmarks/benchmark_hash.py:微基准测试,测量三种实现在典型(bytes, tuple[int])负载下单次调用的延迟。
benchmarks/benchmark_prefix_block_hash.py:端到端块哈希基准测试,运行完整的前缀缓存哈希流水线(hash_block_tokens),测试多个模拟块并报告吞吐量。
支持的算法:sha256、sha256_cbor、xxhash、xxhash_cbor。安装可选依赖以测试所有变体:
如果某个算法的依赖缺失,脚本将跳过该算法并继续执行。
⚡ 请求优先级基准测试¶
展开查看
对 vLLM 中请求优先级的性能进行基准测试。
基础优先级测试¶
python3 benchmarks/benchmark_prioritization.py \
--model meta-llama/Llama-2-7b-chat-hf \
--input-len 128 \
--output-len 64 \
--num-prompts 100 \
--scheduling-policy priority
每个提示多个序列¶
👁️ 多模态基准测试¶
展开查看
对 vLLM 中的多模态请求进行性能测试。
图像(ShareGPT4V)¶
启动 vLLM:
vllm serve Qwen/Qwen2.5-VL-7B-Instruct \
--dtype bfloat16 \
--limit-mm-per-prompt '{"image": 1}' \
--allowed-local-media-path /path/to/sharegpt4v/images
发送带图像的请求:
vllm bench serve \
--backend openai-chat \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset-name sharegpt \
--dataset-path /path/to/ShareGPT4V/sharegpt4v_instruct_gpt4-vision_cap100k.json \
--num-prompts 100 \
--save-result \
--result-dir ~/vllm_benchmark_results \
--save-detailed \
--endpoint /v1/chat/completions
视频(ShareGPT4Video)¶
启动 vLLM:
vllm serve Qwen/Qwen2.5-VL-7B-Instruct \
--dtype bfloat16 \
--limit-mm-per-prompt '{"video": 1}' \
--allowed-local-media-path /path/to/sharegpt4video/videos
发送带视频的请求:
vllm bench serve \
--backend openai-chat \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset-name sharegpt \
--dataset-path /path/to/ShareGPT4Video/llava_v1_5_mix665k_with_video_chatgpt72k_share4video28k.json \
--num-prompts 100 \
--save-result \
--result-dir ~/vllm_benchmark_results \
--save-detailed \
--endpoint /v1/chat/completions
合成随机图像(random-mm)¶
生成合成图像输入以及随机文本提示,无需外部数据集即可对视觉模型进行压力测试。
注意:
- 仅适用于通过 OpenAI 后端(
--backend openai-chat)和端点/v1/chat/completions进行的在线基准测试。 - 视频采样功能尚未实现。
启动服务器(示例):
vllm serve Qwen/Qwen2.5-VL-3B-Instruct \
--dtype bfloat16 \
--max-model-len 16384 \
--limit-mm-per-prompt '{"image": 3, "video": 0}' \
--mm-processor-kwargs max_pixels=1003520
进行基准测试。建议使用 --ignore-eos 标志来模拟真实响应。您可以通过 random-output-len 参数设置输出长度。
示例 1:固定项目数量和单一图像分辨率,强制生成约 40 个 token:
vllm bench serve \
--backend openai-chat \
--model Qwen/Qwen2.5-VL-3B-Instruct \
--endpoint /v1/chat/completions \
--dataset-name random-mm \
--num-prompts 100 \
--max-concurrency 10 \
--random-prefix-len 25 \
--random-input-len 300 \
--random-output-len 40 \
--random-range-ratio 0.2 \
--random-mm-base-items-per-request 2 \
--random-mm-limit-mm-per-prompt '{"image": 3, "video": 0}' \
--random-mm-bucket-config '{(224, 224, 1): 1.0}' \
--request-rate inf \
--ignore-eos \
--seed 42
每个请求的项目数量可通过传递多个图像桶来控制:
--random-mm-base-items-per-request 2 \
--random-mm-num-mm-items-range-ratio 0.5 \
--random-mm-limit-mm-per-prompt '{"image": 4, "video": 0}' \
--random-mm-bucket-config '{(256, 256, 1): 0.7, (720, 1280, 1): 0.3}' \
random-mm 专用标志:
--random-mm-base-items-per-request:每个请求的多模态项目基准数量。--random-mm-num-mm-items-range-ratio:在闭整数区间 [floor(n·(1−r)), ceil(n·(1+r))] 内均匀变化项目数量。设 r=0 保持固定;r=1 允许 0 个项目。--random-mm-limit-mm-per-prompt:每种模态的硬性上限,例如 '{"image": 3, "video": 0}'。--random-mm-bucket-config:字典,映射 (H, W, T) → 概率。概率为 0 的条目将被移除;其余概率将重新归一化,使其总和为 1。图像使用 T=1。视频可设任意 T>1(视频采样暂不支持)。
行为说明:
- 如果请求的基准项目数量在给定每提示限制下无法满足,工具将抛出错误,而不是静默截断。
采样工作原理:
- 根据
--random-mm-base-items-per-request和--random-mm-num-mm-items-range-ratio定义的整数区间均匀采样,确定每个请求的项目数量 k,然后将 k 限制为不超过各模态限制的总和。 - 对于每个 k 项目,根据
--random-mm-bucket-config中的归一化概率采样一个桶 (H, W, T),同时跟踪已添加的每种模态的项目数量。 - 如果某种模态(例如图像)达到
--random-mm-limit-mm-per-prompt的上限,则排除该模态的所有桶,并在继续之前重新归一化剩余桶的概率。 这应被视为边缘情况,如果将--random-mm-limit-mm-per-prompt设置为较大数值,则可避免此行为。注意,这可能导致因引擎配置--limit-mm-per-prompt而引发的错误。 - 生成的请求在
multi_modal_data(OpenAI Chat 格式)中包含合成图像数据。当random-mm与 OpenAI Chat 后端一起使用时,提示保持为文本,多模态内容通过multi_modal_data附加。
嵌入基准测试¶
对 vLLM 中的嵌入请求进行性能测试。
显示更多
文本嵌入¶
与生成模型使用 Completions API 或 Chat Completions API 不同, 您应设置 --backend openai-embeddings 和 --endpoint /v1/embeddings 以使用 Embeddings API。
您可以使用任何文本数据集对模型进行基准测试,例如 ShareGPT。
启动服务器:
运行基准测试:
# 下载数据集
# wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
vllm bench serve \
--model jinaai/jina-embeddings-v3 \
--backend openai-embeddings \
--endpoint /v1/embeddings \
--dataset-name sharegpt \
--dataset-path <your data path>/ShareGPT_V3_unfiltered_cleaned_split.json
多模态嵌入¶
与生成模型使用 Completions API 或 Chat Completions API 不同, 您应设置 --endpoint /v1/embeddings 以使用 Embeddings API。使用的后端取决于模型:
- CLIP:
--backend openai-embeddings-clip - VLM2Vec:
--backend openai-embeddings-vlm2vec
对于其他模型,请在 vllm/benchmarks/lib/endpoint_request_func.py 中添加您自己的实现,以匹配预期的指令格式。
您可以使用任何文本或多模态数据集对模型进行基准测试,只要模型支持即可。 例如,您可以使用 ShareGPT 和 VisionArena 对视觉语言嵌入进行基准测试。
服务并测试 CLIP:
# 在另一个进程中运行
vllm serve openai/clip-vit-base-patch32
# 服务器启动后,依次运行以下命令
# 下载数据集
# wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
vllm bench serve \
--model openai/clip-vit-base-patch32 \
--backend openai-embeddings-clip \
--endpoint /v1/embeddings \
--dataset-name sharegpt \
--dataset-path <your data path>/ShareGPT_V3_unfiltered_cleaned_split.json
vllm bench serve \
--model openai/clip-vit-base-patch32 \
--backend openai-embeddings-clip \
--endpoint /v1/embeddings \
--dataset-name hf \
--dataset-path lmarena-ai/VisionArena-Chat
服务并测试 VLM2Vec:
# 在另一个进程中运行
vllm serve TIGER-Lab/VLM2Vec-Full --runner pooling \
--trust-remote-code \
--chat-template examples/template_vlm2vec_phi3v.jinja
# 服务器启动后,依次运行以下命令
# 下载数据集
# wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
vllm bench serve \
--model TIGER-Lab/VLM2Vec-Full \
--backend openai-embeddings-vlm2vec \
--endpoint /v1/embeddings \
--dataset-name sharegpt \
--dataset-path <your data path>/ShareGPT_V3_unfiltered_cleaned_split.json
vllm bench serve \
--model TIGER-Lab/VLM2Vec-Full \
--backend openai-embeddings-vlm2vec \
--endpoint /v1/embeddings \
--dataset-name hf \
--dataset-path lmarena-ai/VisionArena-Chat
重排序器基准测试¶
对 vLLM 中的重排序请求进行性能测试。
Show more
与生成模型使用 Completions API 或 Chat Completions API 不同, 您应该设置 --backend vllm-rerank 和 --endpoint /v1/rerank 来使用 Reranker API。
对于重排序任务,唯一支持的 dataset 是 --dataset-name random-rerank
启动服务器:
运行基准测试:
vllm bench serve \
--model BAAI/bge-reranker-v2-m3 \
--backend vllm-rerank \
--endpoint /v1/rerank \
--dataset-name random-rerank \
--tokenizer BAAI/bge-reranker-v2-m3 \
--random-input-len 512 \
--num-prompts 10 \
--random-batch-size 5
对于重排序模型,这将创建 num_prompts / random_batch_size 个请求, 每个请求包含 random_batch_size 个 "documents",每个 document 包含接近 random_input_len 个 token。 在上面的示例中,这将产生 2 个重排序请求,每个请求包含 5 个 "documents", 每个 document 包含接近 512 个 token。
请注意,embedding 模型也支持 /v1/rerank。因此,如果您正在运行 embedding 模型, 还需要设置 --no_reranker。因为在这种情况下,query 被服务器视为一个单独的 prompt, 所以这里我们发送 random_batch_size - 1 个 documents,以考虑额外的 prompt(即 query)。 同时,token 计数也会相应调整,以正确报告吞吐量数字。